
Sotsiaalse Analüüsi Meetodite ja Metodoloogia õpibaas
Valimi moodustamine
Mai Beilmann
Andu Rämmer
2025
Sotsiaalteaduslike uuringute tulemused kehtivad tavaliselt mingi inimrühma või nähtuse, mitte kõigi inimeste ja ühiskondlike nähtuste kohta. Sotsiaalteaduslikku uuringut tegema asudes on uurijatel mõttes mõni suurem või väikesem inimrühm või organisatsioon, kelle kohta nende uuringu tulemused midagi ütlema peaksid. Seda inimeste, mõnikord ka nähtuste, organisatsioonide, dokumentide, meediaartiklite, fotode vm materjali koguhulka, mille kohta uuringu tulemused kehtima peaksid, nimetatakse üldkogumiks ehk populatsiooniks. Olenevalt uuringu eesmärgist võib uuringu üldkogum olla näiteks kogu Eesti elanikkond vanuses 15+, 2025. aastal ülikooli lõpetanud, Pärnumaa noorte huviringis osalejad, üliõpilasseltsi X dokumentatsioon, tärkava subkultuuri liikmeskond jne. Vaatluse puhul võib valim moodustuda aga ka näiteks aegadest ja kohtadest, millal ja kus vaatlust läbi viiakse.
Uuringutes keskendutakse harva tervele üldkogumile: kõikseid, kogu populatsiooni haaravaid uuringuid (nt elanikkonna rahvaloendus) viiakse nendega seotud ajakulu ja uurijate kasutada olevate ressursside piiratuse tõttu läbi harva. Kõikse uuringu valimit nimetataksegi kõikseks valimiks. Enamasti ei uurita siiski kõiki huvipakkuva üldkogumi (populatsiooni) liikmeid, vaid nendest moodustatud valimit (vahel nimetatakse seda ka väljavõtuks või väljavõtukogumiks). Valim on seega üldkogumi liikmetest moodustatud osahulk, keda/mida uuritakse ning kellelt / mille kohta kogutud andmete põhjal tehakse järeldusi üldkogumi kohta (joonis 1).
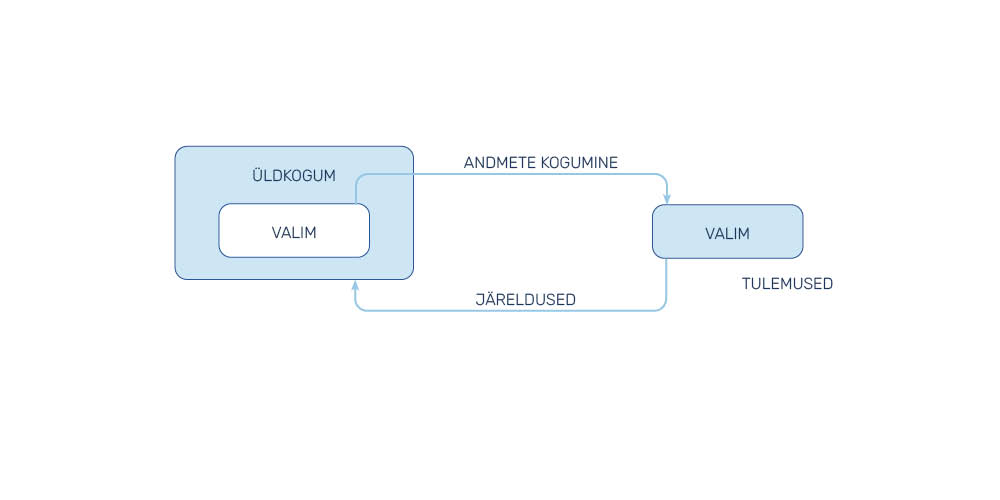
Valimi moodustamine algab üldkogumi määratlemisest ehk otsustamisest, keda või mida uuritakse ning kelle või mille kohta uuringutulemused kehtida saavad. Üldkogumiga tutvumisest algab sobiva andmekogumise meetodi valik ja hilisem andmete tõlgendamine. Valimi moodustamine kujutab endast andmete kogumiseks kõige sobivama üldkogumi osa valikut. Sõltuvalt valimi tüübist saab kogutud andmete põhjal teha erineva üldistusastmega järeldusi üldkogumi kohta. Usaldusväärsete uurimistulemuste saavutamiseks tuleb valimi moodustamisel kasutada üldkogumi iseärasusi arvestavat metoodikat. Laias laastus on valimite moodustamise kriteeriumid a) tõenäosuslikud ja b) mittetõenäosuslikud. Erinevaid tõenäosuslikke ja mittetõenäosuslikke valimitüüpe tutvustame täpsemalt allpool.
Konkreetne valimi moodustamise meetod sõltub uurimistöö eesmärgist ja üldkogumi omadustest. Statistilisel tõenäosusteoorial põhinevad tõenäosuslikud valimi moodustamise kriteeriumid põhinevad uurimisobjektide valimisse sattumise juhuslikkusel ja tõenäosusel. Kui üldkogumi suurust pole võimalik kindlaks määrata, siis kasutatakse paindlikumaid, rohkem sisulistest ja vähem arvulistest näitajatest sõltuvaid mittetõenäosusliku valimi moodustamise kriteeriume. Kvantitatiivsetes uurimustes kogutakse andmeid peamiselt tõenäosuslike valimite ja kvalitatiivsetes uurimustes mittetõenäosuslike valimite abil.
Valimi moodustamise viis sõltub sellest, kuidas, kellelt ja missuguseid andmeid soovitakse koguda. Valimi moodustamise protsess on üsna erinev olenevalt sellest, kas uuringuga soovitakse koguda mõne organisatsiooni töötajatelt töörahuloluhinnanguid või kaardistada, milliseid fotosid postitasid endast perioodil 2020–2025 oma avalikule sotsiaalmeedia profiilile Eesti ministrid. Kindel on aga see, et kuigi ühel juhul moodustavad üldkogumi ühe organisatsiooni töötajad ja teisel juhul teatud ajaperioodil sotsiaalmeediasse postitatud fotod, tuleb mõlemas uuringus moodustada valim. Valimi moodustamist mõjutab ka see, et mitte alati pole üldkogumi suurus täpselt teada ning samuti võivad selle liikmed olla raskesti kättesaadavad. Nii ei saa näiteks üle-eelmises lauses toodud näite puhul loota, et kusagilt oleks võtta täielik nimekiri fotodest, mida Eesti valitsuskabineti liikmed on endast perioodil 2020–2025 sotsiaalmeediasse postitanud. See omakorda tähendab, et sellisel juhul tuleb valida mittetõenäosuslik valim.
Järgnevalt tutvustame eraldi tõenäosuslike ja mittetõenäosuslike valimite moodustamise loogikat ja tüüpe. Valimitüüpide tutvustust alustame aga kõikse valimiga, mille puhul valimit tegelikult ei moodustatagi.
Nagu juba sissejuhatuses öeldud, uuritakse kõikse valimi korral kõiki üldkogumi liikmeid. Kõiksete valimite klassikaline näide on rahvaloendus, mille käigus uuritakse kõiki elanikke nende arvukuse, soo, rahvuse, paiknemise, majandusliku ja sotsiaalse jaotuse ning muude näitajate (nt keelteoskuse) väljaselgitamiseks. Rahvaloenduste korraldamise kalliduse tõttu on viimasel ajal mindud aina enam üle registripõhistele rahvaloendustele, mis ei eelda kogu riigi elanikkonna ükshaaval küsitlemist. Samas võib väikese üldkogumi korral olla kõikse valimi kasutamine igati otstarbekas. Näiteks ei ole 150 õpilasega põhikoolis koolitoiduga rahul olemise uurimiseks mingit mõtet moodustada valimit, vaid küsitluses osalemise võimaluse võiks anda kõigile selle kooli õpilastele.
Tõenäosusliku valimi puhul (seda nimetatakse ka juhuvalimiks) on teada üldkogumi iga „elemendi“ (nt iga inimese) valimisse sattumise tõenäosus. Kvantitatiivsete uuringute valiidsus (st kehtivus) põhineb representatiivsel ehk üldkogumit esindava valimi esinduslikkusel. Valimit, mille põhjal saab teha üldkogumi kohta usaldusväärseid järeldusi, nimetatakse esinduslikuks ehk representatiivseks. Esindusliku valimi korral võib eeldada, et tunnused, mida uuringuga kirjeldatakse, esinevad enam-vähem samasuguse sagedusega nii uuringus osalejate seas kui ka üldkogumis. Nii saab eeldada, et uuringus osalenud inimeste kirjeldamise kaudu saab kirjeldada üldkogumit (st kõiki sihtrühma liikmeid, ka neid, kes uuringus otseselt ei osalenud).
Näitlikustame juhuvalimi moodustamise loogikat värvilistest (kollastest, punastest, rohelistest) kummikarudest moodustatava valimi abil. Oletame, et ühes tohutusuures kommikausis elab kummikarude populatsioon, kus on 40 000 kollast, 30 000 rohelist ja 30 000 punast karu. Kui soovime neist kummikarudest moodustada sajast karust koosneva valimi ja võtame kausist sada juhuslikku karu, on kõige tõenäolisem, et sajast juhuslikult võetud kummikarust 40 on kollased, 30 rohelised ja 30 punased. Kui me seda katset kordame, siis erinevad valimid tõenäoliselt mingi hälbe võrra: mõnikord on tulemuseks 43 kollast, 29 rohelist ja 28 punast karu, teinekord aga 37 kollast, 31 rohelist ja 32 punast karu. Tõenäosus, et juhuvalik hälbib suurel määral kõigi kausis olevate kummikarude vahekorrast ja et saame valimi, kuhu kuulub näiteks 3 kollast, 27 rohelist ja 70 punast kummikaru, on äärmiselt väike (kuigi mitte olematu!).
Sotsiaalteadlasi huvitab see, et nende juhuvalimis oleksid „eri värvi kummikarud“. Mõistagi on sellest, et valimis oleksid heledate ja tumedate juustega või siniste ja pruunide silmadega inimesed esindatud võrdeliselt nende proportsiooniga üldkogumis, märksa olulisem see, et proportsionaalselt üldkogumiga oleksid valimis esindatud eri vanuses, erineva haridustasemega, erinevate väärtuste ja poliitiliste hoiakutega inimesed. Mõningate selliste tunnuste puhul (nt vanus, haridustase) puhul on võimalik hiljem kontrollida, kas üldkogumis esindatud rühmad on valimis proportsionaalselt esindatud. Näiteks esinduslikus Eesti elanikkonna küsitluses peavad proportsionaalselt elanikkonna struktuuriga olema esindatud mehed ja naised, linnade ja maapiirkondade elanikud, kõrgema ja madalama haridusega inimesed jne.
Esindusliku valimi moodustamisel peab igal üldkogumi liikmel olema nullist erinev võimalus valimisse pääseda. See saavutatakse juhusliku valiku abil (siit ka nimetus juhuvalim), mis ei tähenda valimi liikmete meelevaldset valikut, vaid seda, et igal üldkogumi liikmel on kindel nullist erinev võimalus valimisse sattuda ja see tõenäosus on teada. Selleks, et kõigil üldkogumi liikmetel oleks nullist erinev võimalus valimisse sattuda, on meil vaja üldkogumi liikmete nimekirja (nimetatakse ka valimiraamiks). Tõenäosusliku valimi moodustamiseks võib seega olla vajalik üldkogumi nimekirja nõutamine registrist ehk andmekogust, mille andmed on identifitseeritud, regulaarselt uuendatavad ja sisaldavad kõiki üldkogumi liikmeid.
Esindusliku juhuvalimi saamiseks peavad olema täidetud kolm tingimust (Davern 2008):
- uuringu tegijatel on täielik nimekiri üldkogumi elementidest (nt inimestest, majapidamistest, dokumentidest või meediatekstidest), kellel/millel on nullist erinev tõenäosus valimisse sattumiseks;
- elemendid valitakse valimisse juhuslikult;
- kõigilt valimisse sattunud elementidelt kogutakse täielik info.
Tegelikkuses leiab vaevalt aset sotsiaalteaduslikke uuringuid, kus on täielikult täidetud kõik kolm tingimust. Nii näiteks ei sisaldu rahvastikuregistrist saadavas ühe Eesti maakonna elanike nimekirjas inimesed, kes on maakonda kolinud oma elukohaandmeid registris uuendamata. Ometi saame ka sellise natuke ebatäpse nimekirja alusel valimit moodustades siiski palju täpsemaid ja üldistatavamaid järeldusi teha võimaldava andmestiku kui juhuvalimist loobudes. Samuti esineb uuringuis ohtralt olukordi, kus osa uuringu valimisse sattunud inimesi keeldub mingitele küsimustele vastamast, mingite teemade kohta infot avaldamast või üldse uuringus osalemast. See aga tähendab, et päris kõigilt valimisse sattunud inimestelt täieliku info kogumine ei ole sotsiaalteaduslikus uuringus eriti realistlik eesmärk. Realistlikum eesmärk oleks koguda võimalikult paljudelt valimisse sattunud inimestelt võimalikult täielik info. Üldkogumi liikmete nimekirjade ja kogutud vastuste teatav ebatäielikkus on probleem, millega sotsiaalteadustes tuleb lihtsalt leppida. Ainus tingimus, mille puhul pole võimalik absoluutselt mingeid järeleandmisi teha, on reegel, et elemendid valitaks valimisse juhuslikult. Kui seda reeglit eiratakse ning osalejate valimisse sattumine pole rangelt juhuslik, vaid sõltub uuringu tegijate või uuringus osalejate suvast, siis ei ole mingit alust rääkida juhuslikkusest ja tegemist ei ole enam tõenäosusliku valimiga.
Juhuvalimi esinduslikkust mõjutavad valimi moodustamise meetodi kõrval erinevad tegurid, nagu valimiraami valik, valimi suurus, vastamismäär ja mittevastamine/andmelüngad (Davern, 2008).
Valimiraam (ka valikufreim, sample frame)on kogum inimesi, kellel on võimalik sattuda valimisse tulenevalt valimi moodustamise põhimõtetest. Põhimõtteliselt on tegemist üldkogumi liikmete nimekirjaga. Võib öelda, et valimiraami puhul on sisuliselt tegemist uuringu tegijate otsusega, kes saavad nende valimisse kuuluda ja kes jäävad kõrvale. Nii näiteks on kogu riigi täiskasvanud elanikkonna uuringute puhul suhteliselt tavaline, et valimiraamist jäävad välja püsivalt institutsioonides (nt vanglas, hooldekodus) viibivad inimesed. Seega on sellise valimiraamiga saadud valimid esinduslikud riigi täiskasvanud elanikkonna suhtes, välja arvatud institutsioonides viibivad elanikud. Mõnikord seatakse elanikkonna küsitlustes lisaks vanuse alampiirile ka ülempiir, mistõttu võib sellise valimiraami puhul juhtuda, et valim on esinduslik riigi 15–64-aastaste elanike suhtes. Oma valimiraami võidakse piirata aga ka teatud piirkonnaga või muudest kriteeriumitest lähtuvalt.
Valimi maht (sample size) on valimisse kuuluvate inimeste koguhulk ja see peab olema üldkogumi esindamiseks piisava suurusega. Juhuvalimi puhul on soovituslikud valimisuurused seotud sellega, et nende puhul on võimalik välja arvutada valimiviga. Mida suurema juhuvalimiga on tegemist, seda suurem on tõenäosus, et selle põhjal tehtud järeldused üldkogumi kohta peavad paika. (Tasub tähele panna, et kui tegemist ei ole juhuvalimiga, siis valimimahu kasvuga valimi esinduslikkus üldkogumi suhtes ei kasva.) Esindusliku valimi suuruse arvutamiseks on olemas selleks loodud valemitel põhinevad valimimahu kalkulaatorid. Samas tuleb rõhutada, et otsus valimi suuruse kohta, nagu kõik uuringudisaini puudutavad otsused, tuleb teha juhtumipõhiselt, võttes arvesse uuringu eesmärke. Näiteks juhul, kui soovime hiljem teha väga detailset rahvastikurühmade võrdlust, on vaja tavalisest suuremat valimit, et kõigis analüüsi kaasatud alarühmades oleks piisavalt indiviide.
Valimi suuruse kõrval on väga oluline ka vastamismäär (response rate) ehk see, kui suur osa nendest, keda uurida sooviti, tegelikult uuringus osalesid. Kui vastamismäär on madal, siis on mõistagi madal ka uuringutulemuste usaldusväärsus ning tulemuste üldistamisel üldkogumile peab olema äärmiselt ettevaatlik (Fowler, 2012).
Juhuvalimi moodustamiseks on lähtuvalt uurimisülesande püstitusest erinevaid võimalusi.
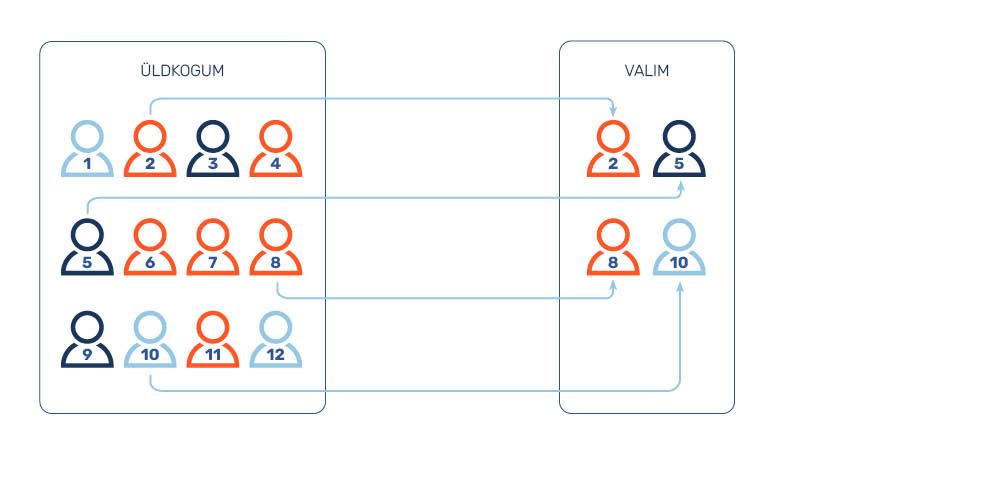
Lihtne juhuvalim (simple random sampling) on valikuviis, mille korral on kõigil üldkogumi liikmetel võrdne tõenäosus valimisse sattuda. Selleks tuleb valimi liikmed selekteerida juhusliku valiku abil. Lihtsa juhuvalimi moodustamist võib piltlikult ette kujutada loteriina, kus kõigi üldkogumi liikmete nimed pannakse loosirattasse. Sealt loositakse täpselt nii palju nimesilte, kui palju on uuringu tegijatel vaja uuringus osalejaid. Lihtsa juhuvalimi ehk juhuväljavõtu moodustamiseks on vajalik uuritava üldkogumi liikmete nimekiri. Päriselus ei pane loomulikult keegi seda nimekirja loosirattasse, vaid üldkogumi nimekirja alusel moodustatakse vajaliku suurusega valim pigem juhuslike arvude generaatori abil.
Lihtsa juhuvalimi moodustamise aluseks võetud üldkogumi liikmete nimekirjas nummerdatakse kõigepealt kõik selle liikmed ning määratakse kindlaks valimi maht ehk valimisse valitavate objektide arv. Seejärel valitakse juhuslike arvude abil üldkogumist välja valimi liikmed. Selleks võib kasutada juhuslike arvude tabelit. Sellise tabeli võib genereerida näiteks MS Exceli juhuarvude generaatori abil, kasutades funktsiooni RANDBETWEEN. Sellisel juhul genereeritakse arvutis valimi soovitud mahule vastav hulk juhuslikke arve, mille alusel järjestatakse valimis olevad üldkogumi liikmed. Genereeritud juhusliku arvudega kokkulangevate järjekorranumbritega üldkogumi liikmed võetakse valimisse (joonis 2). Sellisel viisil tagatakse üldkogumi iga liikme võrdne valimisse sattumise tõenäosus.
Meie värviliste kummikarude näite puhul näeks tuhandest karust koosneva lihtsa juhuvalimi moodustamise protsess välja niimoodi, et kõigepealt 100 000 kummikaru nimekiri nummerdatakse. Seejärel genereerime juhuslike arvude generaatori abil tuhat juhuslikku arvu. Neile arvudele vastavad tuhat juhuslikku kummikaru moodustavad meie valimi.

| Näide Soovime uurida rahulolu ühistranspordiga väikelinnas, kus elanike registrisse on kantud 10 000 täisealist inimest. Nende uurimiseks tuleb moodustada valim suurusega 500 inimest. Respondentide juhuslikuks valikuks kasutame MS Exceli juhuslike arvude genereerimise funktsiooni RANDBETWEEN, mille abil genereerime 500 juhuslikku arvu vahemikus 1–10 000. Kõigepealt määratleme soovitud vahemiku (joonis 3) ning seejärel kopeerime valemi 500 reale. Lõpuks järjestame juhuslikud arvud suuruse järgi, mis võimaldab hõlpsasti selekteerida vastajad üldkogumiks olevast elanike registrinimekirjast. Sel moel saadud juhuslikud arvud tähistavad valimisse sattunud vastajate järjekorranumbrit linnaelanike üldnimekirjas. |
Süstemaatiline juhuvalim (systematic sampling) on valikuviis, mille korral üldkogumist moodustatakse valim üldkogumi nimekirja alusel loeteluviisiliselt, st võttes üldkogumi liikmeid valimisse teatud sammuga (joonis 4).
Süstemaatilise juhuvalimi moodustamisel tuleb väga rangelt jälgida, et üldkogumi liikmete paigutus nimekirjas oleks rangelt juhuslik ja selles ei esineks mingit perioodilisust. Miks perioodilisus üldkogumi liikmete nimekirjas on nii ohtlik, saab selgeks, kui kujutada endale ette olukorda, kus uuringu tegijad soovivad moodustada süstemaatilise juhuvalimi teatud valimisringkonna Riigikogu kandidaatidest. Kuna kandidaate ei ole väga palju, siis võetakse valimisse iga teine kandidaat. Kui kandidaatide nimekiri peaks olema „triibuline“ ehk nimekirjas esinevad mees- ja naiskandidaadid vaheldumisi, oleks tulemuseks kas ainult mees- või ainult naiskandidaatidest koosnev valim. Seega võib perioodilisus üldkogumi nimekirjas süstemaatilise juhuvalimi kasutamisel kaasa tuua valimi märkimisväärse kallutatuse.
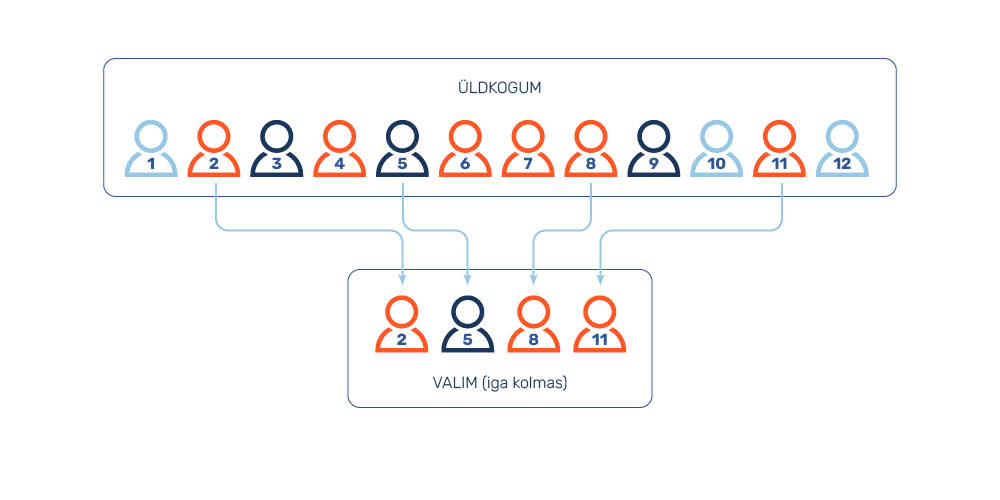
Värviliste kummikarude näite puhul näeks tuhandest karust koosneva süstemaatilise juhuvalimi moodustamise protsess välja niimoodi, et kõigepealt 100 000 kummikaru nimekiri nummerdatakse. Kontrollime, et nimekirjas ei esineks mingit perioodilisust ja et karud ei oleks nimekirjas näiteks värvi järgi süstematiseeritud. Seejärel laseme juhuslike arvude generaatoril genereerida ühe numbri vahemikus 1–100 000. Järgmiseks võtame juhuslike arvude generaatori antud numbrist alates oma valimisse iga sajanda karu.
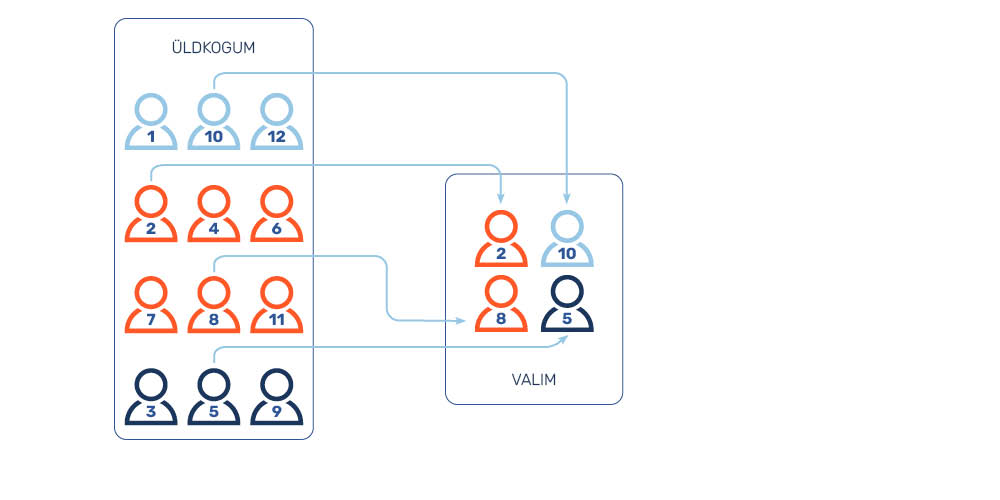
Kihtvalimi (nimetatakse ka stratifitseeritud valimiks, stratified sampling) moodustamisel jaotatakse uuritav üldkogum erinevate uuringu seisukohalt oluliste omaduste (nt sugu, vanus, religioon, elukoht) alusel homogeenseteks rühmadeks (kihtideks). Seejärel moodustatakse igast kihist lihtsa või süstemaatilise juhuvaliku teel esinduslik valim (joonis 5). Kihitunnusteks võetakse tunnused, mis tõenäoliselt mõjutavad uuritavat omadust, näiteks sugu, haridus, eriala, religioon, asula tüüp, institutsiooni osakond jne. Kihtvalimi kasutamine on otstarbekas juhul, kui paljud uuritavad tunnused on kihiti väga erinevad.
Värviliste kummikarude näite puhul näeks kolmest tuhandest karust koosneva kihtvalimi moodustamise protsess välja niimoodi, et valimi moodustamisel ei võta me aluseks mitte 100 000 karu ühtse nimekirja, vaid kolm eraldi nimekirja: kollaste karude nimekirja (40 000 karu), roheliste karude nimekirja (30 000 karu) ja punaste karude nimekirja (30 000 karu). Kõigis neis nimekirjades karud nummerdatakse ning seejärel genereerime juhuslike arvude generaatori abil tuhat juhuslikku arvu iga nimekirja kohta eraldi. Selle tulemusena saame kolm alavalimit, millest ühes on tuhat kollast, teises tuhat rohelist ja kolmandas tuhat punast kummikaru, kes kokku moodustavad 3000 karust koosneva kihtvalimi. Kui meil peaks nüüd tekkima vajadus sellise analüüsi järele, mille tulemusi saaksime üldistada kogu kummikarude üldkogumile, siis oleksid kollased karud meie valimis võrreldes roheliste ja punaste karudega muidugi alaesindatud. Sellest probleemist aitab üle saada aga andmete kaalumine, mis võimaldab tagada erinevate kihtide proportsionaalsuse.
Selline alavalimite (kihtide) moodustamine võib otstarbekaks osutuda näiteks ülikooli vilistlaste uuringus, kui soovime iga valdkonna sees eraldi põhjalikumalt analüüsida vilistlaste rahulolu ülikoolis omandatuga ja hakkamasaamist tööturul. Kõigepealt jagame vilistlased valdkondade kaupa (reaalteadused, sotsiaalteadused, humanitaarteadused, meditsiiniteadus) kihtideks. Võttes aluseks valdkondlikud nimekirjad, moodustame neli soovitud suurusega alavalimit (kihti). Sellega tagame, et meie lõppvalimis on ka väiksema tudengite ja vilistlaste arvuga valdkonnast (meditsiiniteadus) piisavalt vastajaid, et meditsiiniteaduskonna vilistlaste rahulolu detailselt analüüsida.
Klaster- ehk kobarvalimit (cluster sampling) sobib kasutada siis, kui üldkogum jaguneb üksteist välistavatesse rühmadesse ehk klastritesse (st üks inimene ei tohi samaaegselt kuuluda rohkem kui ühte klastrisse). Sellisteks rühmadeks võivad olla näiteks perekonnad, kooliklassid jms. Kui teiste juhuvalimi tüüpide puhul on vajalik uuritavasse üldkogumisse kuuluvate indiviidide nimekiri, siis klastervalimi moodustamisel on vajalik klastrite nimekiri, sest kui ülejäänud juhuvalimi tüüpide puhul valitakse juhuvalikuga valimisse üldkogumisse kuuluvad indiviidid, siis klastervalimi puhul valitakse juhuvalikuga üldkogumist välja klastrid (joonis 6). Klastervalimit sobib seega kasutada ka sellistel juhtudel, kui uuringu tegijatele ei ole kättesaadav üldkogumi indiviidide täielik nimekiri, kuid neil on võimalik moodustada üldkogumi klastrite nimekiri. Klastritesse kuuluvate indiviidide nimekirjad saab välja selgitada uurimise käigus.
Klastervalim moodustatakse klastritest juhuvaliku abil kahes või rohkemas etapis. Üheastmelise klastervalimi korral valitakse üldkogumist juhuvalikuga klastrid ja uuritakse kõiki nendesse kuuluvaid indiviide. Klastrite valikuks võib kasutada erinevaid juhuvaliku meetodeid (lihtne või süstemaatiline juhuvalik, kihtvalik). Kahe- või enamaastmelise klastervalimi (nimetatakse ka mitmetasandiliseks juhuvalimiks) korral tehakse klastri sees veel täiendav indiviidide valik (mõistagi rangelt juhuvalikuga).
Värviliste kummikarude puhul võiksime nüüd korraks ette kujutada, et kummikarud elavad sellises ühiskonnas, kus iga karu saab töötada ainult ühes ettevõttes. Kui me nüüd peaksime soovima uurida võrdlevalt eri värvi kummikarude töörahulolu, siis oleks otstarbekas moodustada individuaalsete kummikarude valimi asemel ettevõtete valim. Niisiis ei ole meil valimi moodustamiseks vaja mitte kõigi kummikarude nimekirja, vaid kõigi kummikarude ettevõtete nimekirja. Järgmiseks nummerdame nimekirjas kõik ettevõtted ning leiame juhuslike arvude genereerimise abil oma valimisse näiteks 100 kummikarude ettevõtet. Kui igas kummikarude ettevõttes töötab keskmiselt 100 karu, siis oleks meie lõppvalim (100 X 100 karu) tavalise rahuloluküsitluse jaoks liiga suur. Parem oleks leida uuringus osalema iga ettevõtte sees loosiga kaks osakonda. Kui ühes osakonnas töötab keskmiselt 10 karu, siis saaksime oma töörahulolu küsitlusele juba mõistliku suurusega valimi ehk 20 X 100 karu.
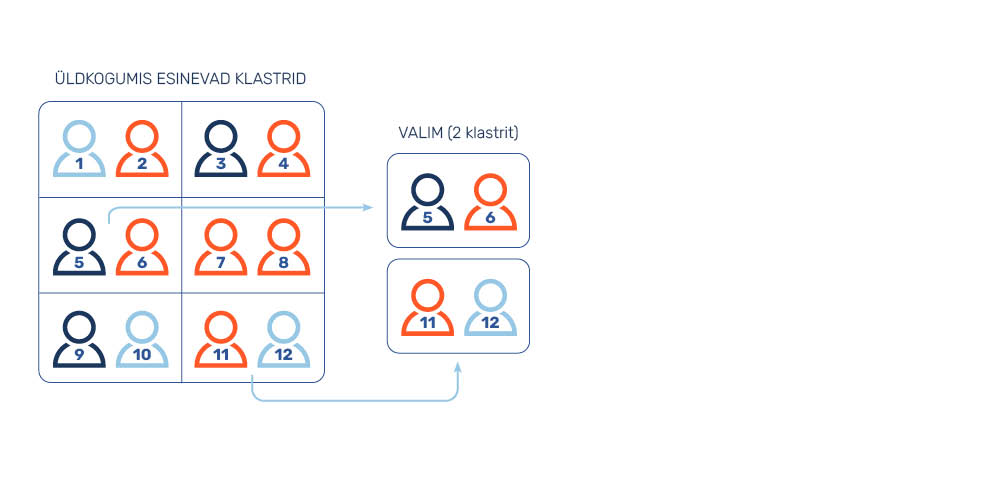
Klastervalimi kasutamine on üsna levinud kooliõpilaste uurimisel. Kui soovime näiteks uurida Eesti gümnasistide heaolu gümnaasiumiõpingute keskel, siis võiks moodustada klastervalimi näiteks Eestis tegutsevate gümnaasiumite üheteistkümnendatest klassidest. Gümnaasiumiastmega koolide üheteistkümnendad klassid tuleb kõigepealt nummerdada ning pärast lihtsa juhuvalikuga uuringus osalevate klasside selektsiooni osalevad uuringus kõik 11. klassi õpilased, kes on küsitluspäeval koolis ja nõus uuringus osalema.
Kuna klastervalimi korral tuleb koostada vaid klastrite nimekirjad, siis on see uurimuse ajaliste ja materiaalsete võimaluste seisukohalt ökonoomne. Õpilaste uurimisel on klastervalimi eeliseks ka võimalus uurida lapsi nende tavapärases klassikeskkonnas.
Mittetõenäosuslikud valimid moodustatakse viisil, mis ei võimalda kõigil üldkogumi liikmetel võrdväärselt valimisse sattuda. Uuringus osalejad valitakse välja eesmärgipäraselt kindlate sisuliste kriteeriumite alusel, kusjuures uuringu tegijad ise määravad kindlaks, millistele kriteeriumitele vastavaid osalejaid valimisse võtta. Mittetõenäosusliku valimi moodustamisel tuginetakse uuringu tegijate varasematele teadmistele uuritavatest sündmustest, juhtumitest, materjalidest ja sihtrühmadest. Seetõttu on oluline, et uuringu tegijad oleksid ennast enne valimi moodustamist viinud põhjalikult kurssi uuritava valdkonna ja uuringu sihtrühmadega.
Mittetõenäsuslike valimite moodustamiseks ei ole vaja üldkogumi liikmete nimekirja. Seega on nende kasutamine juhul, kui üldkogumi nimekirja võtta ei ole, ainuke võimalus uuritavate leidmiseks. Seejuures tuleb arvestada, et selliste vastajate valiku meetodite kasutamisel ei saa uuringutulemuste põhjal teha kaugeleulatuvaid järeldusi ja üldistusi. Kuna tegemist ei ole juhuvalikuga ja üldkogumi liikmete valimisse sattumise tõenäosus ei ole teada, siis ei esinda ükski osaleja kedagi peale iseenda ja kogutud andmetel põhinevaid järeldusi ei saa üldistada ühelegi laiemale üldkogumile (Oppenheim 2000). Eelnevast tulenevalt on mittetõenäosuslikud valimi moodustamise meetodid ebasoosingus kvantitatiivuuringuis, mille tulemusi soovitakse üldistada suurtele üldkogumitele, kuid sobivad suurepäraselt kvalitatiivuuringuis, mille eesmärk ei olegi enamasti üldistatavus, vaid pigem väiksema arvu uuringus osalejate kogemuste sügavuti mõistmine.
Ka mittetõenäosuslike valimite moodustamist mõjutab uurimisprobleemi mitmetahulisus ja uuritava üldkogumi või nähtuse variatiivsus. Näiteks oleneb kvalitatiivuuringutes intervjuude miinimumarv nende pikkusest ja sügavusest, uuritavast teemast, uuritava inimrühma suurusest ja ligipääsetavusest, kasutatavast analüüsimeetodist jms. Seetõttu võib sobiva intervjuude, vaatluste vms arvu planeerimine osutuda küllaltki keerukaks. Üks rusikareegel on aga see, et mida rohkem erinevaid gruppe on kvalitatiivuuringusse kaasatud, seda rohkem intervjuusid, vaatluseid jne on vaja teha. Kvalitatiivuuringuis määratletakse valimi suurus sageli andmete küllastumise (saturatsioon) põhjal. See tähendab, et uusi andmeid kogutakse nii kaua, kuni lisanduvad andmed ei anna enam uut sisulist infot (nt intervjuude puhul hakkavad intervjuudes väljendatud mõtted korduma).
Sihipärase (ka eesmärgipärase/teadliku/taotlusliku/strateegilise/ekspert-, purposive sampling) valimi moodustamisel valib uuringus osalejad uurija ise, lähtudes uuringu eesmärgist ning oma teadmistest. Tegemist on valimitüübiga, mis võimaldabuurijal väga täpselt määratleda, keda uurida tahetakse ja keda valimisse kaasatakse. Olenevalt uurimiseesmärgist võib uuringu tegija püüda leida üldkogumi kõige tüüpilisemaid esindajaid või hoopis võimalikult eristuvaid (mõnikord ka äärmuslikke) uuringus osalejaid (joonis 7). Iseäranis võrdlusuuringute puhul tuleb sageli ette ka seda, et erinevates riikides või piirkondades sama metoodika alusel uuringut läbiviivad teadlased lepivad omavahel kokku mingites kindlates kriteeriumides, millele uuringus osalejad vastama peavad.
Meie kummikarude ühiskonna näitel võib ette kujutada olukorda, kus kummikarude diskrimineerimiskogemuste uurijatele saab teatavaks, et lisaks punastele, kollastele ja rohelistele kummikarudele leidub ka väike hulk siniseid kummikarusid. Neid on kummikarude seas liiga vähe, et neid satuks mõnda juhuvalimisse nii palju, et neid saaks kuidagi kvantitatiivselt uurida. Lähtudes varasemast teadmisest, et vähemused kogevad diskrimineerimist võrreldes enamusega erinevalt (ning pahatihti sagedamini), otsustavad kummikarude diskrimineerimiskogemuste uurijad seetõttu keskenduda just siniste kummikarude uurimisele ning otsivad oma uuringusse sihipäraselt just siniseid kummikarusid. Seega illustreerib see näide juhtumit, kus uuringu tegijate eesmärk on saada valimisse ühe kindla „keskmisest“ eristuva rühma liikmeid.
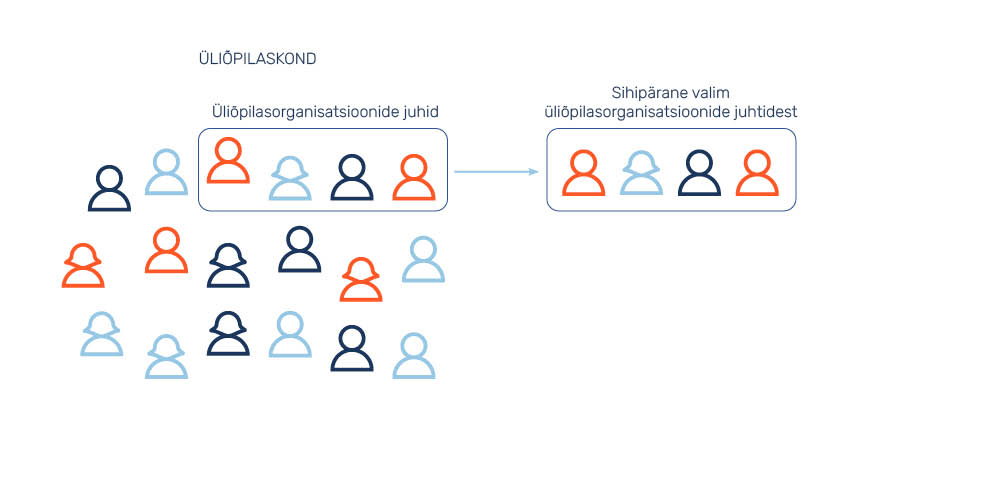
Sihipärase valimi moodustamine võib osutuda otstarbekaks ka näiteks juhul, kui soovime uurida noortekeskuste tegevustes osalevate noorte kogemuslugusid. Kuna kusagil ei ole täielikku nimekirja kõigist Eesti noortest, kes noortekeskusi külastavad, siis ei ole juhuvalimi moodustamine võimalik. Liiati sobib kvalitatiivne lähenemine kogemuslugude kogumiseks oluliselt paremini kui kvantitatiivne. Kuna soovime koguda võimalikult erinevate noorte kogemusi ega keskendu ainult ühele piirkonnale, on sobiv moodustada sihipärane valim erinevates Eesti piirkondades nii maal kui linnas elavatest eri vanuses ja erineva emakeelega noortest, kes noortekeskustes aega veedavad.
Teoreetiline valim (theoretical sampling) on sihipärase valimi erijuht, mille puhul valimi moodustamist suunavad teoorialoome vajadused ning andmekogumise käigus kujunev teoreetiline arusaam uuritavast teemast. Teoreetilise valimiga uuringute puhul toimub andmete kogumine paralleelselt nende analüüsiga ja põhistatud teooria väljaarendamisega. Juba kogutud andmed suunavad uurijat täiendavate andmete kogumisel ja nende analüüsil, kuni tal õnnestub välja töötada veenvad teoreetilised kategooriad. Selline järkjärguline andmete kogumine erineb oma olemuselt sellisest valimite moodustamise põhimõttest, mille aluseks on varasemalt ettemääratud kriteeriumid (nt demograafilised tunnused). Teoreetilise valimi alusel andmete kogumine toimub teoreetilise küllastuse (saturatsiooni) saavutamise põhimõttel: uusi andmeid kogutakse seni, kuni uuringu käigus väljatöötatud uusi teoreetilisi kategooriad saab juba selgelt sõnastada ja neid mõjutavaid uusi nüansse enam ei ilmne. Kuna tegemist on tugevasti teoorialoomega seotud valimitüübiga, siis kasutatakse seda valimitüüpi üleüldse ja iseäranis üliõpilastöödes suhteliselt harva, sest uue teooria loomine on väga ambitsioonikas ettevõtmine, mis enamasti väikesemahulise üliõpilastöö raamesse ei mahu.
Meie kummikarude näite puhul võime teoreetilist valimit ette kujutada selliselt, et kummikarude diskrimineerimiskogemuse uurijad jõuavad siniste kummikarude intervjueerimisel järeldusele, et sellel kummikarude vähemusrühmal on väga sarnased diskrimineerimiskogemused. Sellest johtuvalt tekib uuringu tegijatel esialgne teooria, et sinised kummikarud tajuvad diskrimineerimist teisiti kui kollased, rohelised või punased kummikarud. Loomulikult ei saa nad midagi sellist aga kindlalt väita, sest nad on intervjueerinud üksnes siniseid kummikarusid. Niisiis tingib teoorialoome vajaduse intervjueerida ka piisaval arvul kollaseid, rohelisi ja punaseid kummikarusid, et tekiks võimalus edasi teoretiseerida, kas üldse ja mil viisil eristuvad siniste kummikarude diskrimineerimiskogemused teiste kummikarude omadest.
Teoreetilise valimi kasutamise vajalikkust võib ette kujutada ka bakalaureuseõppe katkestamise põhjuste teooria loomisel. Kuna tegemist on eelnevalt palju uuritud teemaga, on juba ette teada mõned grupid, kellelt tuleb kindlasti andmeid koguda – programmijuhid, õppekorraldajad ning esmajärjekorras muidugi õpingute katkestajad ise. Kui nüüd oletada, et meil on aimdus, et õpingute katkestamise põhjused on mitmekesistunud, ning meie soov on luua teooria, mis kataks lisaks ammu teada tüüpilistele õpingute lõpetamise põhjustele (eriala sobimatus, motivatsioonikadu, rahalised raskused, (vaimse) tervise probleemid jms) ka hiljuti lisandunud põhjuseid, siis tuleb meil hiljutisi õpingute katkestajaid intervjueerida seni, kuni intervjuudes hakkavad katkestamise põhjused korduma. Näiteks võivad esile kerkida keskendumisraskused, mis on tekkinud pärast veebiõppel veedetud aastaid; sõjahirmust ja kliimamuutustest tingitud tunne, et heade õppetulemuste nimel pingutamisel ei ole suurt mõtet jne. Nii võime andmekogumise käigus jõuda näiteks teooriani, et ühiskondlikud kriisid toovad kaasa uusi (või ammu unustatud) põhjuseid kõrgkooliõpingute katkestamiseks.
Lumepallivalim (snowball sampling) on valimitüüp, mille moodustamiseks kasutatakse ära üldkogumi liikmete omavahelisi sidemeid ja võrgustikke. Kõigepealt leitakse üks või mitu valimisse sobivat inimest ja lastakse neil soovitada teisi samasse rühma kuulujaid. Need omakorda juhatavad edasi järgmiste sama rühma liikmete juurde (joonis 8). Lumepallivalimit kasutatakse enamasti selliste rühmade uurimiseks, kelleni uuringu tegijatel on raske jõuda, kuna ametlikest allikatest on võimatu teada saada, kes sellesse rühma kuuluvad ning kui suur see rühm üldse olla võiks. Nii näiteks sobib lumepallivalim hästi eripäraste subkultuuride uurimiseks.
Meie kummikarude uuringu näite põhjal võib siinkohal ette kujutada olukorda, et kummikarude diskrimineerimise uurijad, kes soovivad uurida siniste kummikarude diskrimineerimiskogemusi, tunnevad isiklikult ainult ühte sinist kummikaru. Niisiis pöörduvad nad uuringus osalemise palvega selle sinise kummikaru poole ning paluvad tal ühtlasi soovitada uuringus osalema oma siniseid sugulasi ja tuttavaid. Nood omakorda juhatavad uuringu tegijad järgmiste siniste kummikarudeni.
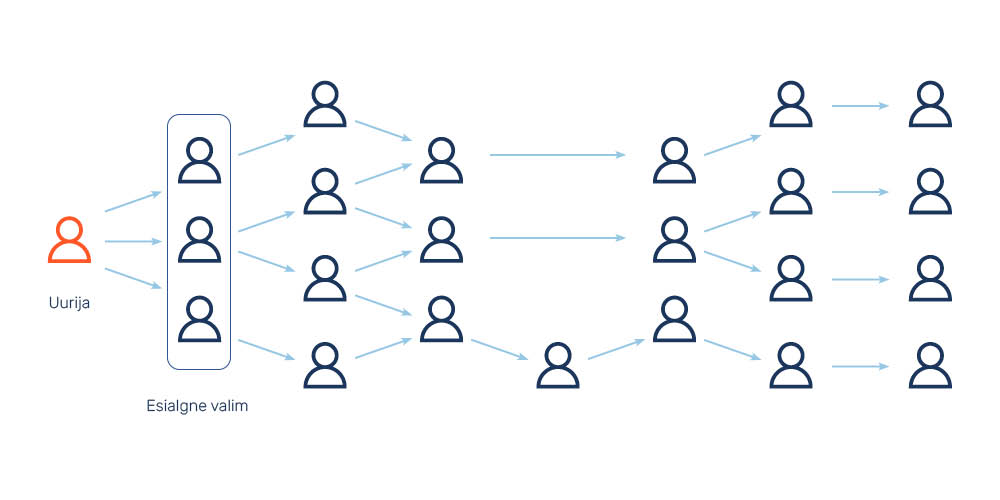
Kui siniste kummikarude puhul on juba peale vaadates selge, kes võiks siniste kummikarude rühma kuuluda ja kes mitte, siis pärisuuringute puhul ei ole lihtsalt inimestele peale vaadates otsustada, kas ta kuulub uuringu üldkogumisse või mitte. Kui me näiteks soovime uurida hemofiilia diagnoosiga laste vanemate kogemusi sotsiaal- ja tervishoiuteenuste kasutamisega, siis ei ole võimalik kusagilt võtta selliste lapsevanemate nimekirja. Uuringut tuleb alustada väikesest arvust lapsevanematest, kelle laps on sellise diagnoosi saanud, ja loota, et nad oskavad oma tutvusringkonnast soovitada teisi sama diagnoosiga laste vanemaid.
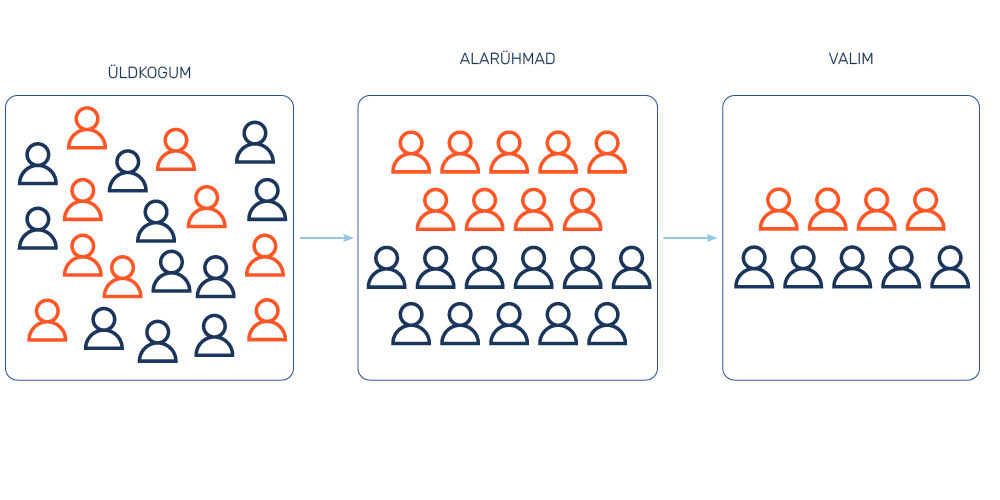
Kvootvalim (quota sampling) on valikumeetod, mille puhul värvatakse inimesi valimisse uuringu tegijate poolt kindlaks määratud kvootide alusel. See tähendab, et uuringu tegijad otsustavad, kui palju mingite rühmade esindajaid tuleb uuringusse kaasata. Enamasti on kvootide aluseks sotsiaaldemograafilised taustatunnused, nagu sugu, vanus ja haridustase.
Kvootvalimi moodustamine on kaheastmeline. Kõigepealt määravad uuringu tegijad kindlaks üldkogumi alarühmad, mis peavad olema uuringus esindatud. Selles osas sarnaneb kvootvalim kihtvalimiga. Valimi moodustamisel määrab rühmadele vastava kvoodi uurija ise. Enamasti võetakse kvootide määramisel arvesse üldkogumi sotsiaaldemograafilist struktuuri. Kui üldkogumisse kuuluvate rühmade (nt vanuse-, soo-, elukoha-, rahvus- ja haridusrühmade) osakaalud on teada, saab määrata proportsionaalsed valimisse kuuluvate rühmade kvoodid. Kvoodi suurus sõltub seega rühma osakaalust üldkogumis: mida suurem on rühma osakaal üldkogumis, seda rohkem määratakse selle liikmeid valimisse (joonis 9). Eesmärk on moodustada valim, milles rühmade osakaalud on proportsionaalsed üldkogumisse kuuluvate alarühmade jaotusega. Pärast üldkogumi alarühmadesse jagamist alustatakse andmekogumist ning seda tehakse kuni kvootide täitumiseni. Erinevalt kihtvalimist on kvootvalim mittetõenäosuslik valim, kuna uuringus osalejaid ei leita mitte juhuslikult, vaid nende valikul lähtutakse pigem mugavuse põhimõttest.
Kui eespool kirjeldatud mittetõenäosuslikud valimitüübid (sihipärane valim, teoreetiline valim, lumepallivalim) sobivad kvalitatiivse uurimisviisiga, siis kvootvalim seostub pigem kvantitatiivse uurimisviisi ja iseäranis küsitlusuuringutega. Kvootvalim on küsitlusuuringu tegemisel kasulik, kui aega on vähe, üldkogumi liikmete nimekiri ei ole kättesaadav, uuringu eelarve on piiratud või kui tulemuste üksikasjalik täpsus ei ole oluline. Mittetõenäosusliku loogika tõttu kasutatakse kvootvalimit akadeemilistes uuringutes pigem harva, aga oma odavuse, kiiruse ja korraldusliku lihtsuse tõttu on see üks eelistatumaid valimitüüpe kommertsuuringutes (Bryman, 2016).
Kummikarude näitel võiks kvootvalimi moodustamine välja näha selliselt, et kummikarude erakondlikke eelistusi uuriv küsitlusfirma lähtub tuhandest karust koosneva valimi moodustamisel eeldusest, et eri värvi kummikarudel on erinevad poliitilised eelistused. Seetõttu seab ta kvoodid, et küsitleda tuleb 400 punast, 300 kollast ja 300 rohelist karu. Küsitlusfirma palgatud küsitlejad jätkavad kummikarude küsitlemist, kuni need kvoodid saavad täidetud. Seejuures võib juhtuda, et näiteks kollaste karude kvoot saab kiiremini täis kui punaste ja roheliste omad. Sellisel juhul lõpetatakse kollaste karude küsitlemine kvoodi täitumisel, kuid jätkatakse punaste ja roheliste karude valimisse värbamist, et kõik kvoodid täita.
Kvootvalim võib olla odav ja korralduslikult lihtne lahendus kaubanduskeskuse klientide rahulolu uurimiseks. Kui on teada, et kaubanduskeskuse klientidest moodustavad 60 protsenti naised ja 40 protsenti mehed, siis saab kliendirahulolu-uuringus seada kvoodi 60 naise ja 40 mehe küsitlemiseks. Küsitlejad värbavad kaubanduskeskuse koridoris kaubanduskeskuse külastajaid rahulolu-uuringule vastama seni, kuni on kogunud vastused 60 naiselt ja 40 mehelt.
Mugavusvalimi (convenience sampling) moodustamisel võetakse uuringus osalema sellised uuritavad, keda uuringu tegijatel on lihtsalt mugav uuringus osalema saada (joonis 10). Sellisteks osalejateks võivad olla näiteks sugulased, sõbrad tuttavad, kesklinna kortermajade alumiste korterite elanikud, õpetajatele õpilased ning õppejõududele üliõpilased. Kuna selline valim ei rajane ühelgi matemaatilisel ega teoreetilisel alusel, vaid põhineb ainult osalejate kättesaadavusel või koostöövalmidusel, siis mingeid üldistusi laiematele üldkogumitele selliste valimite kasutamisel teha ei saa. Selliste valimitega kogutud andmed kajastavad vaid uurijate lähemasse tutvusringi kuulujate ja neile kergemini kättesaadavate inimeste hinnanguid. Sellisel moel moodustatud valimit kasutatakse tavaliselt pilootuuringutes uurijate poolt väljatöötatud küsimustiku või intervjuukava testimiseks.
Meie kummikarude näite puhul küsitleks mugavusvalimit kasutav kummikarude diskrimineerimiskogemusi uuriv punane kummikaru oma sugulasi, sõpru ja töökaaslasi, kes juhtumisi on kõik samuti punased kummikarud. Kogutud andmetest selgub, et ükski uuringus osaleja ei ole diskrimineerimist kogenud. Sellest võib punane kummikaru järeldada, et ükski tema punane sugulane, sõber ega töökaaslane ei ole diskrimineerimist kogenud. Paraku kehtib see tulemus ainult tema tutvusringkonna kohta ning ta ei tohiks mingil juhul teha üldistust kõigi punaste kummikarude kohta, veel vähem järeldada, et ka kollased, rohelised ja sinised kummikarud ei ole diskrimineerimisega kokku puutunud.
Toome teise näite: noorsootööüliõpilane uuris oma bakalaureusetöös noorte toimetulekut koroonapiirangute ajal. Selleks tegi ta oma kursusekaaslaste seas veebiküsitluse. Bakalaureusetöös saab üliõpilane kirjeldada vaid oma kursusekaaslate koroonaaja kogemusi, kuid ta ei saa mingil juhul üldistada tulemusi kõigile Eesti üliõpilastele või veel vähem kõigile Eesti noortele.
Iseselekteerunud valim (nimetatakse ka suvaliseks valimiks või seda kasutavat uuringut valimita uuringuks, self-selection) kujuneb nii, et osalejad valivad end uuringusse ise – uurija seda valikut ei tee (joonis 11). See on kõige kergem, aga ka kõige ebausaldusväärsem valimi moodustamise viis. Sellisel juhul kuuluvad valimisse vaid need, kes on uuringus osalemiseks ise huvi üles näitavad (nt reageerivad mõnel sotsiaalmeediaplatvormil jagatud kutsele või lingile uuringuankeedi juurde). Kuna uurijal puudub igasugune ülevaade ja kontroll, kelleni uuringu info (ja seega ka osalemisvõimalus) jõuab, siis ei ole iseselekteerunud valimiga saadud uuringutulemusi võimalik vähimalgi määral üldistada.
Klassikaline näide iseselekteerunud valimi põhjal üldistuste tegemisega seotud ohtudest pärineb 1936. aastast, mil ajakirjas Literary Digest tehtud küsitlus ennustas USA presidendivalimistel mäekõrguse võidu saavutanud ja ametis olnud Roosevelti valimiskaotust. Kümnest miljonist autoomanike registri ja telefoniraamatute põhjal väljasaadetud küsitluslehest tagastati uurijatele 2,3 miljonit. Suur vastuste hulk ei taganud tulemuse täpsust, sest valimisse lülitati ajakirjalugejate kõrval ka auto- ja telefoniomanike registritesse kuulujad, kelle poolehoid Roosevelti poliitikale oli madalam kui vaesematel ameeriklastel, kes ei saanud Suure Depressiooni ajal endale autosid ja telefone lubada. Hilisem analüüs selgitas välja, et küsitlusele vastasid ülekaalukalt need inimesed, kes ei olnud Roosevelti poliitikaga rahul.
Toome ka ühe näite bakalaureusetööst, kus üliõpilane uurib noorte seas toitumisega seotud eetilisi valikuid. Ta viib läbi veebiküsitluse, mida jagab taimetoitlaste ja veganite sotsiaalmeediagruppides, kus palub uuringukutset ka edasi jagada. Andmeid analüüsides selgub, et 80% meessoost vastajatest on otsustanud eetilistel põhjustel liha söömisest täielikult loobuda. Kui üliõpilane oma bakalaureusetöös kirjutab, et 80% tema küsitlusele vastanud meestest on lihatoodete söömisest loobunud, on tegemist korrektse andmete tõlgendamisega. Küll aga ei saa üliõpilane seda tulemust kuidagi üldistada ning väita, et 80% noortest meestest (Eestis, Euroopas, maailmas) oleks lihasöömisest loobunud.
Bryman, A. (2016). Social research methods. Oxford: Oxford University Press.
Davern, M. E. (2008). Representative Sample. P. J. Lavrakas (toim), Encyclopedia of Survey Research Methods. Volume 2 [N–Z], (lk 720–721). Thousand Oaks: Sage.
Fowler, F. J. (2012). Survey Research Methods. Thousand Oaks: SAGE Publications. Oppenheim, A. N. (2000). Questionnaire design, interviewing and attitude measurement. London, New York: Continuum.
Lagerspetz, M. (2023). Ühiskonna uurimise meetodid: sissejuhatus ja väljajuhatus. Tallinn: Tallinna Ülikooli Kirjastus.
Tiit, E.-M. ja Tooding, L.-M. (2019). Statistikaleksikon. Tartu: Tartu Ülikooli Kirjastus.
Tooding, L.-M. (2015). Andmete analüüs ja tõlgendamine sotsiaalteadustes. Tartu: Tartu Ülikooli Kirjastus. Traat, I. ja Inno, J. (1997). Tõenäosuslik valikuuring. Tartu: Tartu Ülikooli Kirjastus.