
Sotsiaalse Analüüsi Meetodite ja Metodoloogia õpibaas
Q-metodoloogia
Marit Napp
2025
Q-metodoloogia on meetod, mille abil uuritakse inimeste seisukohti, arvamusi, uskumusi ja tundeid erinevates küsimustes. Inimeste seisukohad on sageli subjektiivsed, kuid Q-meetodi abil saab välja selgitada, kuidas need subjektiivsed arvamused omavahel kattuvad või erinevad. Selle asemel et küsida inimestelt jah/ei küsimusi või anda neile mõni küsimustik, esitatakse Q-metodoloogilises uuringus osalejatele teatud hulk uuritava teemaga seotud väiteid ning palutakse neil need järjestada vastavalt sellele, kui palju nad nende väidetega nõustuvad või ei nõustu. Q-meetod võimaldab seega tuvastada arvamuste rühmi või mustreid, mis kajastavad erinevaid väärtushinnanguid, maailmavaateid jms.
Q-hulga ehk Q-valimi moodustavad uurija koostatud väited uuritava teema kohta. Q-hulga koostamine algab koondkogumi määratlemisega. Koondkogum on suur hulk arvamusi, uskumusi, seisukohti vms – see sisaldab kõike, mida inimesed võiksid uuritava teema kohta mõelda, tunda või öelda. Koondkogum on nii-öelda toormaterjal Q-hulga jaoks. Koondkogumi võib moodustada näiteks
- intervjuudest,
- sotsiaalmeediast,
- ajalehtedest ja blogidest,
- akadeemilistest allikatest,
- igapäevastest vestlustest või oma tähelepanekutest.
Koondkogumi koostamisest võib mõelda kui ajurünnaku etapist, pärast mida saab asuda Q-hulka koostama. Üldistatult on Q-hulga loomise juurde võimalik asuda kahel moel – tulemuseks on kas struktureeritud või struktureerimata Q-hulgad (Watts ja Stenner, 2012). Struktureeritud Q-valimi moodustamiseks jaotab uurija uurimisteema komponentideks mõne teooria või lihtsalt uurimise ja vaatluse tulemusena. Näiteks võib uurija leida kümme võtmekomponenti, mida Q-hulk peab katma. Lähtuvalt igast komponendist luuakse seejärel väited või seisukohad eesmärgiga, et lõplik Q-hulk sisaldaks näiteks viit või kuut väidet, mis kataksid iga komponendi eri aspekte. Struktureerimata Q-valimi moodustamine algab sarnaselt, st peamiste teemade kaardistamisega. Seda tehakse selleks, et mõista uurimisteemat tervikuna, mitte teema tükeldamise eesmärgil. Peamine eesmärk on luua väidete kogum, mis kataks uuritavat teemat, mitte lähtuda ettemääratud väidete piirarvudest.
Olenemata sellest, kumb lähenemine valida, on oluline pidada kinni järgmisest.
- Eemaldada korduvad või väga sarnased väited.
| Näide Koondkogumis on väited „Me peame keskkonda rohkem kaitsma“ ning „Keskkonnakaitse peaks olema prioriteet“. Sisuliselt on tegemist sama mõttega, mistõttu jätame alles ainult ühe. Võime mõtet ka täpsustada, näiteks „Valitsus peaks kehtestama rangemad reeglid looduse kaitseks“. |
- Lihtsustada keerukat sõnastust, et iga väide oleks arusaadav.
| Näide Leidsime sotsiaalmeedia postitusest järgmise mõtte: „Virtuaalsete õppevahendite kasutusvõimalused võimaldavad konstruktiivset teadmiste omandamise protsessi“. Tegemist on üsna keerulise väitega, mida võime lihtsustada näiteks „Digitaalsed tööriistad aitavad teadmisi paremini omandada“. |
- Veenduda, et kaetud on eri vaatenurgad (positiivsed, negatiivsed ja neutraalsed).
| Näide Oleme leidnud koondkogumisse palju väiteid, mis kiidavad tervislikku eluviisi, näiteks „Liikumine parandab tuju“, „Tervislik eluviis aitab ennetada haiguseid“ jne. Tahame Q-hulka kaasata ka teistsuguseid seisukohti, mistõttu lisame mõtte „Tervisliku eluviisi järgimine on ajakulukas“. |
- Kontrollida kallutatust – Q-hulk ei tohi toetada vaid ühte meelsust.
| Näide Kõik väited Q-hulgas kritiseerivad sotsiaalmeediat (nt „Sotsiaalmeedia tekitab sõltuvust“, „Sotsiaalmeedia rikub noorte vaimset tervist“). Toome sisse ka teisi seisukohti, nt „Sotsiaalmeedia aitab hoida kontakti välismaal elavate sõpradega“ jne. |
- Testida arusaadavust – kõik väited peavad olema selged ja ühemõttelised.
| Näide Väide „Hariduse mõju indiviidile võib varieeruda sõltuvalt mitmetest faktoritest, sealhulgas, aga mitte ainult, motivatsioonist ja õpetamisviisist“ on raskesti mõistetav. Sõnastame väite ümber järgnevalt: „Õpilase edasijõudmine sõltub õpetaja oskusest teda motiveerida.“ |
Kui suur peaks olema Q-hulk? Tavaliselt sisaldab Q-valim 40–80 väidet, aga ka rohkem ning vähem on aktsepteeritav – näiteks Eestis läbiviidud jälgimisrakenduste uuringus (Sukk ja Siibak, 2022) kasutati edukalt 28 väidet sisaldanud Q-hulka. Vaatamata sellele, kui suur on lõplik Q-hulk, tuleks esialgu moodustada pigem rohkem väiteid, mida siis pilootuuringu käigus vähendada ja viimistleda. Tungivalt soovituslik on, et teised uurijad heidaksid samuti pilgu esialgsele Q-hulgale – see aitab parandada sõnastust, vähendada kordusi, luua uusi väiteid ja saada kinnitust Q-hulga piisavale katvusele uuritava teema suhtes (Watts ja Stenner, 2012).
Q-metodoloogilisse uuringusse tuleks leida osalejad, kellel on uuritava teemaga seoses oma seisukoht ning kelle vaatenurgad on uuringu jaoks olulised (Watts ja Stenner, 2012). Seetõttu eelistatakse Q-metodoloogias sihipärast valimit. Q-metodoloogiline uuring ei vaja suurt hulka osalejaid ehk P-hulka, sest uurimuse eesmärk on tuvastada olemasolevad vaatenurgad, mitte teha suuri üldistusi (Brown, 1980). Soovituslik on, et osalejate arv oleks väiksem kui väidete arv Q-hulgas (Watts ja Stenner, 2012; Tiidenberg jt, 2020).
| Näide Soovime kaardistada õpetajate seisukohti õppetöös digitehnoloogia kasutamise asjus. Meie eesmärk on leida valimisse õpetajad, kes esindavad erinevaid vaateid, mistõttu valime uuringusse õpetajad, kes näiteks on väga positiivsed digivahendite suhtes,on skeptilised või kriitilised,töötavad erinevates kooliastmetes (alg-, põhi-, keskkool),töötavad erinevates piirkondades (maa- ja linnakoolid),on erineva kogemusega (algajad vs. kogenud). |
Traditsiooniliselt antakse Q-hulk osalejatele juhuslikult nummerdatud kaartide vormis, igal kaardil üks väide Q-hulgast. Lisaks paberkaartidele pakuvad head võimalust väidete sorteerimiseks ka veebikeskkonnad (nt https://qsortouch.com/, https://qmethodsoftware.com/, https://www.qsortware.net/). Iga osaleja peab väited järjestama mingil skaalal – näiteks „nõustun kõige rohkem“ kuni „nõustun kõige vähem“ või „kõige tähtsam“ kuni „kõige vähem tähtis“ jne. Esmalt peab osaleja väited hoolikalt läbi lugema – nii saab väidetest hea ülevaate. Osaleja võiks sorteerimisega alustada juba lugemise ajal, jagades väited esmalt kolme hunnikusse: väited, millega ta näiteks üldiselt nõustub, need, millega ta ei nõustu, ja need, mille suhtes tal seisukohta ei ole. Seejärel palutakse osalejal sorteerida kaardid vastavalt etteantud jaotusele – selleks võib olla skaala -3…+3, -6…+6 jne. Joonisel 1 on toodud fikseeritud jaotus skaalal -3…+3, kus -3 tähistab „nõustun kõige vähem“ ning +3 „nõustun kõige rohkem“. Fikseeritud jaotus tähendab, et osaleja saab iga skaalapunkti alla märkida kindla arvu väiteid. Selline tingimus tähendab, et osaleja peab väiteid sorteerima taustsüsteemi (ehk oma suhtumist teistesse väidetesse) arvesse võttes.
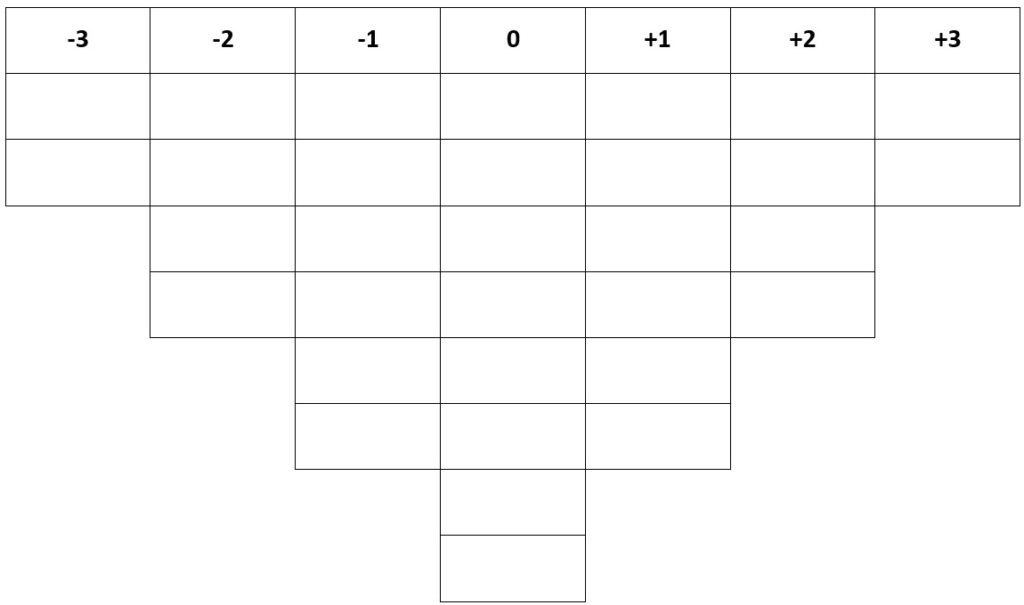
Ka joonisel 2 on toodud fikseeritud jaotus, aga skaalal -6…+6. Tegemist on lamedama jaotuskõveraga. Järsemat ja kitsamat jaotuskõverat (joonis 1) soovitatakse juhul, kui osalejad ei pruugi teemaga väga tuttavad olla või kui teema on eriti keeruline. See võimaldab osalejatel paigutada rohkem väiteid jaotuse keskossa. Madalam või lamedam jaotuskõver sobib paremini teemade puhul, mis on lihtsamad või mille kohta on osalejatel head teadmised.
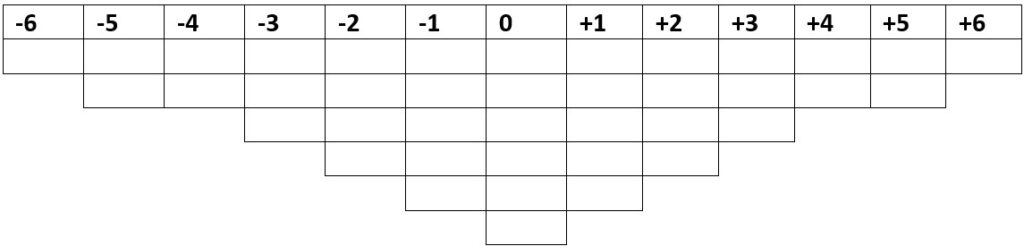
Väiteid on võimalik sorteerida ka fikseerimata jaotuse alusel – see tähendab, et osaleja saab iga skaalapunkti alla märkida piiramatu arvu väiteid. Nii fikseeritud kui ka fikseerimata jaotus on Q-metodoloogias aktsepteeritav – Browni (1980) uuring näitab, et statistilised erinevused erinevate jaotuste vahel on peaaegu olematud.
Lisaks väidete sorteerimisele on soovituslik viia läbi intervjuu (nt paluda osalejal oma seisukohti täpsustada või küsida lisainformatsiooni). See on suureks abiks edasises interpretatsioonis.
Väidete sorteerimisele järgneb faktoranalüüs. Analüüsi peamine eesmärk on leida ühised vaatenurgad ehk faktorid, mis iseloomustavad osalejaid, kes on väited sarnaselt sorteerinud. Järgnevalt vaatleme faktoranalüüsi programmis Ken-Q Analysis (https://shawnbanasick.github.io/ken-q-analysis/), mis on üks enim kasutatavaid vabavaralisi programme Q-metodoloogilise uurimuse andmete analüüsimiseks. Programmist on olemas ka allalaaditav versioon KADE, mis toimib täpselt samamoodi.
Kasutame näitena andmeid laste jälgimisrakenduste uuringust (Sukk ja Siibak, 2022). Uuringus osales 20 last, kes märkisid 28 väidet skaalale −5…+5, kus −5 tähendas „kõige vähem nõus“ ja +5 „kõige rohkem nõus“. Lapsed said samuti paigutada väiteid kategooriasse „0“, kui nad ei olnud kindlad, kas nad nõustuvad või mitte. Uuringus kasutati fikseerimata jaotust (st osalejad said iga skaalapunkti alla märkida piiramatu arvu väiteid), sest uurijad leidsid, et nii-öelda vaba ulatusega sorteerimine annab noortele osalejatele rohkem vabadust (vt ka Bolland, 1985). Esimene samm on andmete sisestamine. Kõige lihtsam on kogutud andmed (st iga osaleja järjekorda seatud väited) sisestada Exceli malli, mille saab programmi avalehelt alla laadida. Valida on kahe faili vahel. Kui uuringus on kasutatud fikseeritud jaotust (st osaleja saab iga skaalapunkti alla märkida kindla arvu väiteid), tuleks valida esimene fail (Type 1). Kui uuringus on kasutatud fikseerimata jaotust, tuleks valida teine fail (Type 2). Kuna meie näites kasutati fikseerimata jaotust, valime Exceli faili nr 2. Fail avaneb Google Spreadsheeti keskkonnas, kust tuleks see alla laadida (keskkonnas on fail üksnes vaatamiseks) .xlsx formaadis. Exceli failis on märgitud, kuhu ja mida sisestada (vt vahelehed, mille nimes sisaldub Example). Esimesele lehele (Name) tuleks märkida projekti pealkiri (joonis 3) – valime selleks näiteks „Lapsed“.
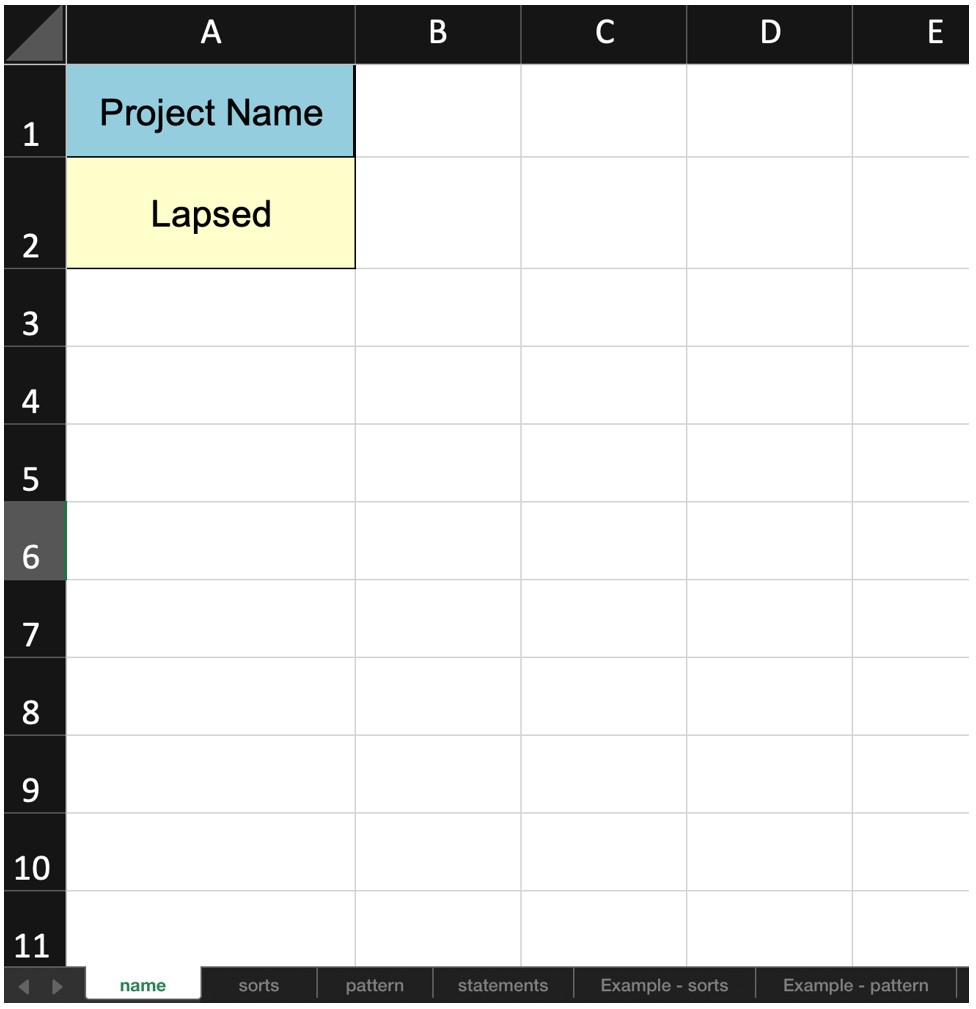
Järgmisena tuleb sisestada vahelehele Sorts iga osaleja sorteeritud väited. Tulpa A tuleb märkida iga osaleja nimi (või kood). Järgmistesse tulpadesse tuleb märkida kõikide väidete väärtused – tulpa B tuleb märkida esimese väite väärtus (st millisele skaalapunktile osaleja väite asetas), tulpa C teise väite väärtus, tulpa D kolmanda väite väärtus jne. Iga osaleja sorteerimised tuleb märkida eraldi reale (joonis 4).

Järgmisena tuleb faili märkida skaala (Pattern). Viimane on oluline juhul, kui uuringus on kasutatud fikseeritud jaotust – sellisel juhul tuleks faili kirjutada, mitu väidet mingi skaalapunkti all on. Kui mõne skaalapunkti all pole ühtegi väidet, tuleb märkida 0. Kuna meie näites kasutati fikseerimata jaotust, märgime skaala alla lihtsalt esimese osaleja väidete sorteerimise mustri (joonis 5). Näeme, et esimene osaleja on -5 alla märkinud viis väidet, -4 alla ühe väite jne.

Viimasena tuleb faili lisada kõik väited (Statements). A-tulbas on väite number, B-tulpa tuleb märkida väide. Kõik väited tuleb lisada üksteise alla (joonis 6).

Lõpetuseks tuleb fail salvestada ning laadida üles programmi veebilehele (Drag and drop …) (joonis 7).

Programm näitab seejärel projekti kokkuvõtet – nimi, osalejate ja väidete arv, skaala (NB! Oluline üksnes juhul, kui uuringus on kasutatud fikseeritud jaotust!) ning väited. Vajutades nuppu „Start Analysis“, saame asuda andmeid analüüsima.
Analüüs algab korrelatsioonimaatriksi arvutamisest (Correlations), mis näitab üksikute Q-järjestuste (sorteerimiste, ladumiste) vahelisi sarnasusi (ja ka erinevusi). Tabelis 1 on näha laste järjestuste vahelised korrelatsioonid.
Tabel 1. Osalejate järjestuste korrelatsioonimaatriks
| Osaleja | L01 | L02 | L03 | L04 | L05 | L06 | L07 | L08 | L09 | L10 | L11 | L12 | L13 | L14 | L15 | L16 | L17 | L18 | L19 | L20 |
| L01 | 100 | -33 | 51 | 39 | 31 | 20 | 46 | 57 | 44 | 34 | -36 | 45 | 26 | 53 | 8 | 45 | 49 | 54 | 18 | 28 |
| L02 | -33 | 100 | -12 | -28 | -13 | 7 | 14 | 1 | -27 | 5 | 45 | -14 | -8 | -3 | 19 | 5 | -21 | -18 | 1 | 22 |
| L03 | 51 | -12 | 100 | 49 | 51 | 41 | 43 | 53 | 61 | 57 | -32 | 75 | 48 | 58 | 20 | 12 | 41 | 47 | 30 | 26 |
| L04 | 39 | -28 | 49 | 100 | 14 | 57 | 44 | 43 | 55 | 55 | -24 | 46 | 38 | 37 | -8 | 49 | 44 | 38 | 29 | 39 |
| L05 | 31 | -13 | 51 | 14 | 100 | 33 | 52 | 44 | 45 | 34 | -1 | 60 | 35 | 42 | 26 | 22 | 49 | 16 | 60 | 25 |
| L06 | 20 | 7 | 41 | 57 | 33 | 100 | 67 | 46 | 64 | 80 | -15 | 61 | 42 | 62 | -11 | 51 | 40 | 26 | 43 | 39 |
| L07 | 46 | 14 | 43 | 44 | 52 | 67 | 100 | 69 | 57 | 75 | -2 | 54 | 54 | 52 | 19 | 58 | 72 | 42 | 61 | 58 |
| L08 | 57 | 1 | 53 | 43 | 44 | 46 | 69 | 100 | 54 | 46 | -29 | 64 | 74 | 58 | 26 | 47 | 65 | 55 | 25 | 47 |
| L09 | 44 | -27 | 61 | 55 | 45 | 64 | 57 | 54 | 100 | 67 | -45 | 66 | 44 | 59 | 5 | 42 | 67 | 45 | 43 | 55 |
| L10 | 34 | 5 | 57 | 55 | 34 | 80 | 75 | 46 | 67 | 100 | -26 | 68 | 40 | 59 | 6 | 51 | 58 | 45 | 62 | 55 |
| L11 | -36 | 45 | -32 | -24 | -1 | -15 | -2 | -29 | -45 | -26 | 100 | -36 | -33 | -13 | 10 | 7 | -37 | -57 | 5 | -2 |
| L12 | 45 | -14 | 75 | 46 | 60 | 61 | 54 | 64 | 66 | 68 | -36 | 100 | 46 | 54 | 8 | 37 | 53 | 50 | 43 | 36 |
| L13 | 26 | -8 | 48 | 38 | 35 | 42 | 54 | 74 | 44 | 40 | -33 | 46 | 100 | 39 | 19 | 19 | 48 | 53 | 26 | 27 |
| L14 | 53 | -3 | 58 | 37 | 42 | 62 | 52 | 58 | 59 | 59 | -13 | 54 | 39 | 100 | 5 | 35 | 25 | 39 | 17 | 28 |
| L15 | 8 | 19 | 20 | -8 | 26 | -11 | 19 | 26 | 5 | 6 | 10 | 8 | 19 | 5 | 100 | 18 | 26 | 25 | 24 | 50 |
| L16 | 45 | 5 | 12 | 49 | 22 | 51 | 58 | 47 | 42 | 51 | 7 | 37 | 19 | 35 | 18 | 100 | 43 | 12 | 53 | 66 |
| L17 | 49 | -21 | 41 | 44 | 49 | 40 | 72 | 65 | 67 | 58 | -37 | 53 | 48 | 25 | 26 | 43 | 100 | 48 | 60 | 61 |
| L18 | 54 | -18 | 47 | 38 | 16 | 26 | 42 | 55 | 45 | 45 | -57 | 50 | 53 | 39 | 25 | 12 | 48 | 100 | 3 | 25 |
| L19 | 18 | 1 | 30 | 29 | 60 | 43 | 61 | 25 | 43 | 62 | 5 | 43 | 26 | 17 | 24 | 53 | 60 | 3 | 100 | 59 |
| L20 | 28 | 22 | 26 | 39 | 25 | 39 | 58 | 47 | 55 | 55 | -2 | 36 | 27 | 28 | 50 | 66 | 61 | 25 | 59 | 100 |
Positiivne korrelatsioon tähendab, et kaks osalejat sorteerisid väiteid sarnaselt, ning mida suurem on arv (kuni 100 või 1,00), seda sarnasemad on kahe osaleja järjestused. See tähendab, et osalejad nõustusid ja ei nõustunud samade väidetega, asetades need jaotuses ligikaudu samadele positsioonidele. Näite põhjal saame näiteks öelda, et osalejad L04 ja L06 jagavad mõnda vaatenurka (57 või 0,57), samas kui osalejate L02 ja L06 järjestustes (7 või 0,07) on vähe ühist. Negatiivne korrelatsioon tähendab, et kaks osalejat järjestasid väited vastupidisel viisil. Mida väiksem on arv (kuni -100 või 0,1), seda enam vastanduvad nende seisukohad – millega üks osaleja oli täielikult nõus, teine tõenäoliselt ei nõustunud, ja vastupidi. Tabelist 1 näeme, et näiteks osalejad L01 ja L02 on järjestanud väiteid nii, et need vastanduvad osaliselt teineteisele. Miks on korrelatsioon oluline? Positiivne korrelatsioon aitab tuvastada osalejate rühmi, kelle vaatenurgad kattuvad – nendest rühmadest saavad hiljem faktorid ehk ühised vaatenurgad. Negatiivne korrelatsioon viitab võimalikele vastandlikele seisukohtadele ja aitab mõista, kui erinevad võivad vaatenurgad üksteisest olla.
Järgmiseks eraldame korrelatsioonimaatriksist faktorid (Factor Extraction). See on protsess, mille käigus tuvastatakse mustrid või jagatud vaatenurgad erinevate sorteerimiste seas. Iga faktor esindab osalejaid, kes reastasid väited sarnaselt – see tähendab, et neil on sarnane arusaam uuritavast teemast. Faktorid eraldatakse tsentroidide meetodil (Centroid Factors) ehk kasutades lihtsat summeerimist – tsentroididest võib mõelda kui aritmeetilisest keskmisest, mis iseloomustavad seoseid kõikide väidete sorteerimiste vahel (Tiidenberg jt, 2020). Siin tasub märkida, et lisaks tsentroidide meetodile on olemas ka faktoranalüüs peakomponentide meetodil (Principal Component Analysis ehk PCA), mille eesmärk on osalejaid võimalikult hästi eristavate koondtunnuste leidmine, mis kirjeldaksid võimalikult suure osa tunnuste koguvariatiivsusest (Tooding, 2014). Q-metodoloogias eelistatakse siiski tsentroidide meetodit, sest tegemist on uurimusliku meetodiga, mis annab uurijale rohkem vabadust otsustada, millised faktorid välja tuua ja kuidas neid pöörata (Stephenson, 1953; Watts ja Stenner, 2012; Tiidenberg jt, 2020).
Üks olulisi mõttekohti faktorite eraldamisel on küsimus, mitu faktorit eraldada. Watts ja Stenner (2012) soovitavad alustada põhimõttest üks faktor iga kuue väite kohta. See tähendab, et kui uuringus on näiteks 12 väidet, võiks alustada kahe faktori eraldamisega, 20 väite puhul nelja faktoriga jne. Ken-Q Analysis programm lubab eraldada kuni kaheksa faktorit (vrd PQMethod programm seitse faktorit), mis tähendab, et väga suure väidete hulga puhul tulebki alustada Ken-Q-s just kaheksa faktori eraldamisest. Meie näites on 28 väidet, mistõttu alustame viie faktoriga. Programm annab meile esialgse ehk pööramata faktormaatriksi (Unrotated Factor Matrix) (tabel 2).
Tabel 2. Pööramata faktormaatriks
| Nr | Osaleja | Faktor 1 | Faktor 2 | Faktor 3 | Faktor 4 | Faktor 5 |
| 1 | L01 | 0,62 | -0,2604 | 0,0268 | -0,1913 | 0,0476 |
| 2 | L02 | -0,12 | 0,4626 | 0,3687 | 0,2927 | -0,203 |
| 3 | L03 | 0,70 | -0,2824 | -0,1439 | 0,2411 | 0,0884 |
| 4 | L04 | 0,62 | -0,0791 | 0,0487 | -0,0745 | 0,0069 |
| 5 | L05 | 0,56 | 0,0905 | -0,3641 | 0,3288 | 0,1166 |
| 6 | L06 | 0,67 | 0,0696 | 0,1185 | 0,3188 | 0,089 |
| 7 | L07 | 0,80 | 0,3568 | 0,2263 | 0,1283 | 0,1155 |
| 8 | L08 | 0,79 | -0,0809 | 0,2753 | 0,0198 | 0,0632 |
| 9 | L09 | 0,83 | -0,0518 | -0,1766 | -0,0679 | 0,0049 |
| 10 | L10 | 0,80 | 0,1691 | 0,0078 | 0,1198 | 0,0271 |
| 11 | L11 | -0,35 | 0,584 | 0,1319 | 0,2199 | -0,2114 |
| 12 | L12 | 0,80 | -0,0911 | -0,1733 | 0,2323 | 0,0509 |
| 13 | L13 | 0,62 | -0,1358 | 0,1295 | 0,0803 | 0,0358 |
| 14 | L14 | 0,64 | -0,1111 | 0,2867 | 0,0863 | 0,1112 |
| 15 | L15 | 0,20 | 0,2203 | 0,0103 | -0,0613 | 0,0205 |
| 16 | L16 | 0,56 | 0,358 | 0,3497 | -0,201 | 0,1502 |
| 17 | L17 | 0,79 | 0,1309 | -0,1575 | -0,2836 | 0,0335 |
| 18 | L18 | 0,60 | -0,3818 | 0,1816 | -0,1457 | 0,1143 |
| 19 | L19 | 0,56 | 0,6518 | -0,3985 | 0,0079 | 0,3019 |
| 20 | L20 | 0,61 | 0,5005 | 0,2535 | -0,3907 | 0,2164 |
| Omaväärtused | 8,1836 | 1,941 | 1,0014 | 0,8462 | 0,327 | |
| % variatiivsus | 40 | 10 | 5 | 4 | 2 |
Faktormaatriks on faktorlaadungite (Factor Loadings) tabel, mis näitab iga ladumise esialgset seotust ehk korrelatsiooni iga faktoriga. Iga faktorit iseloomustab ka omaväärtus (Eigenvalue) ning variatiivsus (Explained Variance). Omaväärtus näitab, kui suure osa variatiivsusest ehk informatsioonist järjestustes kirjeldab üks faktor. Mida kõrgem on omaväärtus, seda rohkem osalejate järjestustest see faktor selgitab. Variatiivsus näitab, kui suure osa kogu andmestikust kirjeldab üks faktor. Omaväärtused on kõige sagedamini kasutatav kriteerium selle otsustamiseks, mitu faktorit eraldada ja lõpliku lahenduse jaoks alles jätta (Watts ja Stenner, 2012). Madalaid omaväärtusi – alla 1 – peetakse sageli nii-öelda lävendiks. See tähendab, et alles jäetakse ainult need faktorid, mille omaväärtus on 1 või rohkem. Seda nimetatakse Kaiseri-Guttmani kriteeriumiks (Guttman, 1954; Kaiser, 1960). Nii omaväärtus kui ka variatiivsus annavad meile hea ülevaate eraldatud faktori statistilisest tugevusest ja selgitusvõimest.
Tabelist 2 nähtub, et üksnes esimese kolme faktori omaväärtus on >1. See viitab, et valitud viiefaktoriline lahendus ei ole sobiv ja võiksime liikuda edasi kolme faktoriga. Kolm esimest faktorit kirjeldavad 55% (40%+10%+5%) kogu uuringu variatiivsusest. Heaks tulemuseks loetakse 35%-40% või üle selle (Kline, 1994), mis näitab samuti, et kolmefaktoriline lahendus võiks olla sobilik. Seega liigume järgmisesse etappi kolme faktoriga.
Pärast faktorite eraldamist tuleb neid pöörata, et iga sorteerimine (st iga osaleja väidete järjestus) oleks võimalikult tugevalt seotud ainult ühega faktoritest. Selleks kasutame Varimaxi, mille abil pööratakse faktorite telgi viisil, mis aitab mõista, millisesse faktorisse üks või teine osaleja kuulub. Varimax lihtsustab seega tulemuste tõlgendamist. Lisaks Varimaxile võib faktoreid pöörata ka käsitsi (sh Ken-Q programmis), ent see nõuab uurijalt vilumust Q-metodoloogias, mistõttu me käsitsi pööramist siin peatükis ei kirjelda. Küll aga tuleks käsitsi arvutada statistiliselt oluline faktorlaadung (Significant Factor Loading), mis näitab, (a) millised järjestused on tugevalt seotud ainult ühe faktoriga, (b) millised järjestused on tugevalt seotud mitme faktoriga ning (c) millised järjestused ei ole tugevalt seotud mitte ühegi faktoriga. Valem selleks on järgnev:
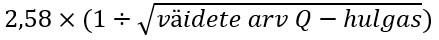
Meie näites oleks statistiliselt oluline faktorlaadung seega:
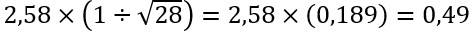
Varimaxi pööramise tulemusi näeme tabelis 3. Tabelis on märgitud (Flagged) ka need järjestused, mis ühte või teist faktorit kujundavad. Selle sammu saab lasta programmil automaatselt teha (tabelis 3 just nii ka on), ent mõistlik on teha seda hoopis käsitsi. Miks? Sest automaatne märgistamine ei pruugi anda parimat lahendust. Tabelist 3 nähtub, et osalejad L07, L10, L15 ja L20 on faktoritest välja jäänud, sest nad ei ole tugevalt ainult ühe faktoriga seotud (tingimus a).
Tabel 3. Pööratud faktormaatriks koos faktorit kujundavate järjestustega (statistiliselt oluline faktorlaadung 0,49)
| Q sorteerimine | Faktor 1 | Faktor 2 | Faktor 3 | |||
| L01 | 0,6379 | Märgitud | 0,1974 | -0,0752 | ||
| L02 | -0,205 | -0,0705 | 0,5641 | Märgitud | ||
| L03 | 0,6904 | Märgitud | 0,2767 | -0,1278 | ||
| L04 | 0,5587 | Märgitud | 0,2774 | 0,0686 | ||
| L05 | 0,303 | 0,5778 | Märgitud | -0,0845 | ||
| L06 | 0,5464 | Märgitud | 0,3344 | 0,2289 | ||
| L07 | 0,5417 | 0,4983 | 0,512 | |||
| L08 | 0,7701 | Märgitud | 0,2248 | 0,2485 | ||
| L09 | 0,6417 | Märgitud | 0,5544 | -0,037 | ||
| L10 | 0,5705 | 0,5319 | 0,2425 | |||
| L11 | -0,5215 | Märgitud | 0,0197 | 0,454 | ||
| L12 | 0,6417 | Märgitud | 0,5181 | -0,0662 | ||
| L13 | 0,595 | Märgitud | 0,2269 | 0,0501 | ||
| L14 | 0,645 | Märgitud | 0,1549 | 0,1713 | ||
| L15 | 0,0573 | 0,2177 | 0,1922 | |||
| L16 | 0,3818 | 0,2899 | 0,5558 | Märgitud | ||
| L17 | 0,5305 | 0,6158 | Märgitud | 0,1004 | ||
| L18 | 0,7326 | Märgitud | 0,0252 | -0,0568 | ||
| L19 | 0,0106 | 0,9078 | Märgitud | 0,2688 | ||
| L20 | 0,3006 | 0,4994 | 0,5495 | |||
| % variatiivsus | 29 | 17 | 9 |
Kuna me soovime analüüsi kaasata võimalikult palju osalejaid (ja nende järjestusi), on võimalik tõsta statistiliselt olulist faktorlaadungit (Watts ja Stenner, 2012). Liikudes näiteks 0,54 peale, saame kolmandasse faktorisse kaasata veel ühe järjestuse (L20).
Tabel 4. Pööratud faktormaatriks koos faktorit kujundavate järjestustega (statistiliselt oluline faktorlaadung 0,54)
| Q sorteerimine | F1 | F2 | F3 | |||
| L01 | 0,64 | Märgitud | 0,20 | -0,08 | ||
| L02 | -0,21 | -0,07 | 0,56 | Märgitud | ||
| L03 | 0,69 | Märgitud | 0,28 | -0,13 | ||
| L04 | 0,56 | Märgitud | 0,28 | 0,07 | ||
| L05 | 0,30 | 0,58 | Märgitud | -0,08 | ||
| L06 | 0,55 | Märgitud | 0,33 | 0,23 | ||
| L07 | 0,54 | Märgitud | 0,50 | 0,51 | ||
| L08 | 0,77 | Märgitud | 0,22 | 0,25 | ||
| L09 | 0,64 | 0,55 | -0,04 | |||
| L10 | 0,57 | Märgitud | 0,53 | 0,24 | ||
| L11 | -0,52 | 0,02 | 0,45 | |||
| L12 | 0,64 | Märgitud | 0,52 | -0,07 | ||
| L13 | 0,60 | Märgitud | 0,23 | 0,05 | ||
| L14 | 0,65 | Märgitud | 0,15 | 0,17 | ||
| L15 | 0,06 | 0,22 | 0,19 | |||
| L16 | 0,38 | 0,29 | 0,56 | Märgitud | ||
| L17 | 0,53 | 0,62 | Märgitud | 0,10 | ||
| L18 | 0,73 | Märgitud | 0,03 | -0,06 | ||
| L19 | 0,01 | 0,91 | Märgitud | 0,27 | ||
| L20 | 0,30 | 0,50 | 0,55 | Märgitud | ||
| % variatiivsus | 29 | 17 | 9 |
Nii oleme jõudnud kolmefaktorilise lahenduseni, kus 17 osaleja järjestust 20st on tugevalt seotud ühega kolmest faktorist (tabel 4). Meil on ka kaks osalejat, kelle ladumised ei ole seotud mitte ühegi faktoriga, ning üks osaleja, kes on seotud rohkem kui ühe faktoriga. Kokku kirjeldavad meie kolm faktorit 55% ladumiste variatiivsusest. Kuna Q-meetodi eesmärk on tuvastada arvamuste rühmi või mustreid, siis paraku jäävad kolme osaleja järjestused tõlgendusest välja.
Nüüd saame oma analüüsi alla laadida – mugav on seda teha Exceli formaadis. Seejärel ootab ees faktorite interpreteerimine, mille eesmärk on avastada, mõista ja selgitada faktorite kaudu esile kerkinud vaatenurki.
Faktorite interpreteerimisel on oluline roll faktorskooridel (Factor Array) ehk individuaalsetel faktorite väärtustel. Arvutuslikult on faktorskoorid faktorlaadungite kaalude summad, mille sellesse faktorisse kuuluvad osalejad väidetele andsid (Tiidenberg jt, 2020). Faktorskoorid arvutatakse standardiseerituna (z-skooridena). Et erinevaid vaatenurki oleks lihtsam võrrelda, teisendatakse z-skoorid seejärel tagasi sama skaalaga täisarvudeks, mida kasutati algselt väidete järjestamisel (meie näites -5…+5). Seega võime faktorskooridest mõelda kui ideaalsest järjestusest. Samal ajal aitavad faktorskoorid mõista sarnasusi ja erinevusi eri vaatenurkade sees ja vahel (Watts ja Stenner, 2012; Tiidenberg jt, 2020). Ken-Q Analysis teeb meie eest eespool kirjeldatu ära – faktorskoorid leiame Exceli failis vahekaardilt Consensus-Disagreement (tabel 5). Tabelis on toodud kõik näidisuuringu väited ning nende seos tekkinud vaatenurkadega (faktoritega) – mida suurem on mõne väärtus, seda suurem on nõustumine väitega selles vaatenurgas. Näiteks näeme, et väitega number 1 nõustuvad osalejad kõigis kolmes faktoris, samal ajal kui väitega number 3 nõustuvad üksnes osalejad faktoris kaks (osalejad faktorites üks ja kolm on väitele vastu). Niiviisi tabelile otsa vaadates hakkab kujunema esmane pilt sellest, kuidas tekkinud „tüübid“ (st osalejad faktorites üks, kaks ja kolm) väiteid on sorteerinud ja milline on nende nägemus uuritavast teemast.
Tabel 5. Väited ning faktorskoorid
| Väite nr | Väide | Faktor 1 | Faktor 2 | Faktor 3 |
| 1 | Emad-isad ja lapsed peavad üksteist usaldama. | 5 | 4 | 4 |
| 2 | Vanemad ei tohiks oma lapse asukohta jälgida ilma sellest temaga rääkimata. | 0 | 2 | 5 |
| 3 | Kui ema-isa jälgivad oma lapse asukohta, aga ei ütle seda talle, siis see tähendab, et nad ei usalda oma last. | -4 | 5 | -5 |
| 4 | Ma tunnen end turvaliselt, kui ema-isa teavad, kus ma asun. | 5 | 5 | 0 |
| 5 | Ma arvan, et oht luurab iga nurga peal. | -3 | -5 | -5 |
| 6 | Mu vanemad saavad mulle alati appi tulla, kui nad teavad, kus ma asun. | 4 | 5 | 0 |
| 7 | See, kui mu vanemad teavad, kus ma asun, ei pruugi mind ohtlikus olukorras tegelikult aidata. | -2 | -5 | -4 |
| 8 | Lastele ei meeldi, et vanemad nende asukohta jälgivad. | -5 | -1 | -1 |
| 9 | Ma tahan vahel olla üksi ega soovi, et ema-isa teaksid, kus ma olen. | -5 | -5 | 5 |
| 10 | Kui ema-isa jälgivad pidevalt lapse asukohta, siis nad ei austa tema soovi vahel üksi olla. | 0 | 4 | -2 |
| 11 | Ma tunnen end vahel halvasti, kui vanemad minu asukohta jälgivad. | -5 | -5 | -3 |
| 12 | Ma arvan, et saan hakkama ilma, et mu vanemad mind pidevalt jälgiksid. | -5 | 4 | 0 |
| 13 | Ma arvan, et ma pean ise vastutama selle eest, et mul oleks turvaline ja hea olla. | 4 | -4 | -5 |
| 14 | Vanemad peaksid lastelt küsima, kas neile meeldib, kui vanemad laste tegemistel silma peal hoiavad. | 4 | 5 | 5 |
| 15 | Lapsed peavad teadma, miks nende vanemad nende asukohta teada tahavad. | 5 | 5 | 5 |
| 16 | Vanemad võiksid lapsi vähem jälgida. | -5 | -3 | -1 |
| 17 | Vanematel on õigus oma lapsi kontrollida. | 5 | -2 | -1 |
| 18 | Vanemad võivad otsustada selle üle, kus nende lapsed käivad. | 2 | -1 | 5 |
| 19 | Ma pean oma vanemate sõna kuulama. | 5 | 0 | 5 |
| 20 | Kuna mu ema/isa ostis mulle telefoni, siis pean ma tegema nii, nagu tema ütleb. | -1 | -1 | -5 |
| 21 | Minu vanematel on õigus teada, kes on minu sõbrad. | 5 | 5 | 5 |
| 22 | Minu vanematel on õigus teada, kas ma olen koolis, trennis või kusagil mujal. | 5 | 5 | -1 |
| 23 | Ema-isa tunnevad end paremini, kui nad teavad, kus ma olen. | 5 | 5 | 5 |
| 24 | Mu vanemad kardavad minu pärast ja sellepärast tahavad nad teada, kus ma olen. | 5 | -1 | 2 |
| 25 | Ma arvan, et mu vanemad muretsevad liiga palju. | -1 | -5 | -5 |
| 26 | Lapsed püüavad leida viise, et oma vanemate silma alt pääseda. | -1 | 0 | 5 |
| 27 | Lapsed suudavad edukalt hoiduda vanemlikust jälgimisest, kui nad seda tahavad. | 0 | 5 | 4 |
| 28 | Kui laps ei taha, et vanem teda jälgiks, võib ta hakata oma tegevusi varjama. | -1 | 0 | 4 |
Lisaks faktorskooridele aitavad tekkinud vaatenurkade tõlgendamisel kaasa faktorit eristavad väited (Distinguishing Statements for Factor n) ja konsensuslikud väited (Consensus Statements). Need leiame samuti Exceli faili vahekaartidelt. Eristavad väited toob Ken-Q Analysis välja iga faktori kohta eraldi.
Tabelis 6 on toodud faktorit 1 eristavad väited – see tähendab väiteid, mis aitavad faktorit teistest eristada. Eristavad väited toovad esile selle arvamuse, mis omane nendele osalejatele, kes kuuluvad sellesse faktorisse (ehk jagavad seda vaatepunkti). Konsensuslikud väited (tabel 7) viitavad nendele väidetele, millega osalejad on kõikides faktorites nõustunud.
Tabel 6. Faktorit 1 eristavad väited
| Väite nr | Väide |
| 1 | Emad-isad ja lapsed peavad üksteist usaldama. |
| 19 | Ma pean oma vanemate sõna kuulama. |
| 17 | Vanematel on õigus oma lapsi kontrollida. |
| 13 | Ma arvan, et ma pean ise vastutama selle eest, et mul oleks turvaline ja hea olla. |
| 28 | Kui laps ei taha, et vanem teda jälgiks, võib ta hakata oma tegevusi varjama. |
| 25 | Ma arvan, et mu vanemad muretsevad liiga palju. |
| 26 | Lapsed püüavad leida viise, et oma vanemate silma alt pääseda. |
| 5 | Ma arvan, et oht luurab iga nurga peal. |
| 12 | Ma arvan, et saan hakkama ilma, et mu vanemad mind pidevalt jälgiksid. |
| 8 | Lastele ei meeldi, et vanemad nende asukohta jälgivad. |
| 11 | Ma tunnen end vahel halvasti, kui vanemad minu asukohta jälgivad. |
Tabel 7. Konsensuslikud väited
| Väite nr | Väide |
| 7 | See, kui mu vanemad teavad, kus ma asun, ei pruugi mind ohtlikus olukorras tegelikult aidata. |
| 14 | Vanemad peaksid lastelt küsima, kas neile meeldib, kui vanemad laste tegemistel silma peal hoiavad. |
| 21 | Minu vanematel on õigus teada, kes on minu sõbrad. |
| 23 | Ema-isa tunnevad end paremini, kui nad teavad, kus ma olen. |
Järgnevalt pakun välja faktori 1 võimaliku tõlgenduse. Meeldetuletuseks – uurisime laste mõtteid seoses jälgimisrakenduste kasutamisega. Faktor 1 kirjeldab nii-öelda ühte tüüpi lapsi, kelle vaatenurga me tänu Q-metodoloogiale avastasime – nimetame neid lapsi näiteks kuulekateks lasteks. Faktorisse 1 kuulub 11 osalejat. Kirjelduse juurde on sulgudesse märgitud väite number ja faktorskoor (vt ka tabel 5). Lisaks on oluline märkida, et faktori tõlgendusele on kaasa aidanud ka läbiviidud intervjuud (vt lähemalt väidete sorteerimise alajaotusest).
| Faktor 1: kuulekas laps Faktor 1 esindab lapsi, kes tunnevad end mugavalt, kui nende vanemad kasutavad jälgimistehnoloogiaid. Sellesse faktorisse kuuluvad lapsed on leppinud jälgimisega (8: −5; 11: −5; 16: −5) ega tunne, et jälgimisrakendused või vanemad rikuksid nende privaatsust (9: −5). Nad usuvad, et vanematel on täielik õigus teada, kus nad viibivad (22: +5) ja kellega nad sõbrustavad (21: +5). Lisaks on faktoriga 1 seotud lapsed veendunud, et vanematel on õigus neid kontrollida (17: +5) ja lapsed peavad tegema nii, nagu vanemad ütlevad (19: +5), sest vanemad teavad, mis on neile parim. Kokkuvõttes usaldavad need lapsed täielikult oma vanemaid ja aktsepteerivad nende toodud jälgimise põhjendusi. Seega võib faktoriga 1 seotud lapsi pidada kuulekaiks, „headeks lasteks“, kes ei sea kahtluse alla vanemate autoriteeti ega jälgimise põhjuseid. Need lapsed ei näe jälgimist kui praktikat, mille kaudu nad loobuvad kontrollist oma isikliku teabe üle. Seda hoiakut illustreerib fakt, et faktor 1 alla kuuluvad lapsed ei kipu midagi vanemate eest varjama ega püüa vältida jälgimist (26: −1; 28: −1). Siiski, vaatamata oma üldisele kuulekusele, tahavad nad teada, miks neid jälgitakse (15: +5). Lapsed leiavad, et tunnevad end turvalisemalt, kui vanemad teavad, kus nad on (4: +5). Nad usuvad, et vanemad muretsevad nende pärast (24: +5) ja et jälgimine võib vanemaid rahustada (23: +5). Siiski tekib huvitav paradoks – selle faktori lapsed tahavad teada, miks neid jälgitakse, ja nad eelistaksid, et seda arutataks peres (14: +4; 15: +5). Samal ajal oleksid nad valmis leppima olukorraga ka siis, kui neile jälgimisest ei räägitaks (3: −4). Sellised vaated illustreerivad taas nende laste kuulekat loomust – neil on ettekujutus, kuidas nad tahaksid, et asjad oleksid, kuid nad on valmis sellest loobuma, kui vanemad otsustavad teisiti. Kuigi selle faktori lapsed on teadlikud asukoha jälgimisest, tunnevad end sellega mugavalt ning on valmis usaldama nii jälgimisrakendusi kui ka oma vanemaid, et hädaolukorras abi saada (6: +4; 7: −2), usuvad nad samas kindlalt, et vastutavad ise oma turvalisuse ja heaolu eest (13: +4). Kuigi nad ei arva, et saaksid hästi hakkama ilma vanemate jälgimiseta (12: −5), teavad nad, et ei saa pimesi loota jälgimisrakendustele ning peavad olema teadlikud olukordadest, kuhu nad sattuda võivad. |
Samamoodi tuleks kirja panna faktorite 2. ja 3. tõlgendused. Iga faktor avab uuritavat teemat oma nurga alt, ent üheskoos loovad nad tervikliku pildi uuringus osalenute seisukohtadest.
Bolland, J. M. (1985). The search for structure: an alternative to the forced-sort technique. Political Methodology 11, 91–107.
Brown, S. R. (1980). Political subjectivity: Applications of Q methodology in political science. New Haven: Yale University Press.
Guttman, L. (1954). Some necessary conditions for common factor analysis. Psychometrika, 19(2), 149–161.
Kaiser, H. F. (1960). The application of electronic computers to factor analysis. Educational and Psychological Measurement, 20(1), 141–151.
Kline, P. (1994). An Easy Guide to Factor Analysis. London: Routledge.
Stephenson, W. (1953). The Study of Behaviour: Q Technique and its Methodology. Chicago: University of Chicago Press.
Sukk, M. ja Siibak, A. (2022). „My mom just wants to know where I am“: Estonian pre-teens’ perspectives on intimate surveillance by parents. Journal of Children and Media, 16(3), 424–440.
Tiidenberg, K., Masso, A., Pilt, M. ja Laineste, L. (2020). Diskursusanalüüs andmestunud ühiskonnas. A. Masso, K. Tiidenberg ja A. Siibak (toim), Kuidas mõista andmestunud maailma? (lk 476–486). Tallinn: TLÜ Kirjastus.
Tooding, L.-M. (2014). Faktoranalüüs. K. Rootalu, V. Kalmus, A. Masso ja T. Vihalemm (toim), Sotsiaalse analüüsi meetodite ja metodoloogia õpibaas. https://samm.ut.ee/faktoranalyys/
Van Exel, J. ja de Graaf, G. (2005). Q methodology: A sneak preview. https://qmethod.org/wp-content/uploads/2016/01/qmethodologyasneakpreviewreferenceupdate.pdf
Watts, S. ja Stenner, P. (2012). Doing Q methodological research. Theory, method & interpretation. London: Sage.
Masso, A., Kello, K. ja Jakobson, V. (2013). Üleminek riigikeelsele gümnaasiumiõppele: vilistlaste seisukohtade Q-metodoloogiline diskursusanalüüs. Eesti Rakenduslingvistika Ühingu aastaraamat 9, 161–179.
Männiste, M. ja Masso, A. (2020). „Three Drops of Blood for the Devil“: Data Pioneers as Intermediaries of Algorithmic Governance Ideals. Mediální studia, 14(1), 55–74.
Stenner, P., Watts, S. ja Worrell, M. (2017). Q Methodology. C. Willig & W. Stainton Rogers (toim), The SAGE Handbook of Qualitative Research in Psychology, (lk 212–237). London: Sage.
Sukk, M. ja Siibak, A. (2021). Caring dataveillance and the construction of „good parenting“: Estonian parents’ and pre-teens’ reflections on the use of tracking technologies. Communications, 46(3), 446–467.
Kilvits, C. (2022). Eesti keskkonnavaldkonna avalike teenistujate suhtumine harrastusteadusesse keskkonnakorralduses. Magistritöö. Eesti Maaülikool. https://dspace.emu.ee/server/api/core/bitstreams/4d899f97-e226-4431-bf72-526230a0ca56/content