Sotsiaalse Analüüsi Meetodite ja Metodoloogia õpibaas
Andmestike haldamine
Ave Kovaljov
2014, täiendatud ja parandatud 2025
Enamasti ei ole olemasolevates andmestikes andmed sellisel kujul, et neid saaks kohe iga uurimuse jaoks analüüsida. Igal uurimusel on oma spetsiifika, mistõttu tuleb sageli alustada andmete korrastamisest ja andmestiku valmisseadmisest selleks, et oleks üldse võimalik sellist analüüsi teha, nagu on vaja. Selles peatükis antaksegi ülevaade, kuidas tervet andmestikku ja ka üksikuid tunnuseid analüüsiks ette valmistada. Täpsemalt, selles peatükis käsitletakse seda, kuidas muuta andmestiku struktuuri, liita erinevaid andmestikke ning kodeerida ümber tunnuseid.
Analüüsi tegema hakates ei ole tavaliselt vaja kõiki andmestikus olevaid tunnuseid, vaid ainult väikest osa neist. Sel puhul on mõistlik salvestada vajalikud tunnused eraldi andmestikuna ja edaspidi opereerida vaid nendega.
Kasutades Euroopa Sotsiaaluuringu (Edaspidi ESS) 2020. aasta andmestikku, teeme väiksema andmestiku, milles on ainult Eesti andmed ja need tunnused, mis puudutavad tööga seotud temaatikat.
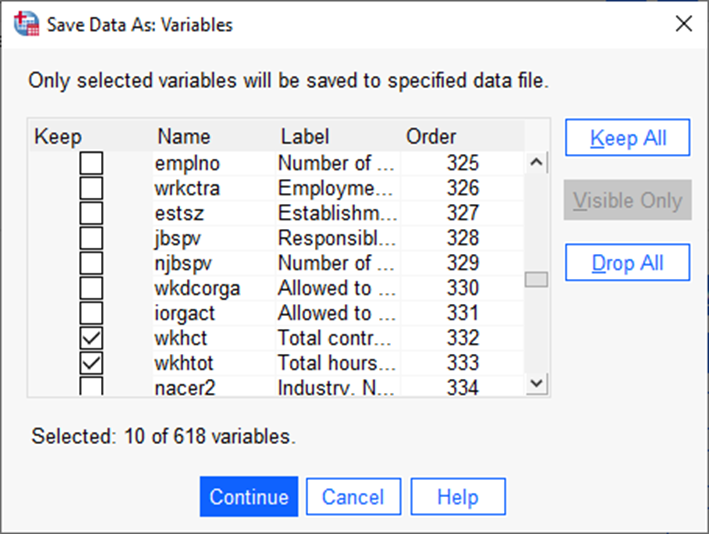
Valime Euroopa Sotsiaaluuringu 2020. aasta andmestikust (andmed saab siit: http://www.europeansocialsurvey.org -> Data -> ESS Data Portal -> ESS round 10 – 2020. -> ESS10 integrated file. Andmefaili alla laadimine eeldab registreerumist) tunnused idno (hilisemaks andmestike liitmiseks on oluline, et võtaksime kaasa ID, mis on igal andmereal unikaalne), riik (cntry), kaalud (dweight, pspwght, pweight, anweight), tööturu staatus (mnactic), lepingujärgsed töötunnid nädalas (wkhct) ja kõik töötunnid nädalas kokku (wkhtot) ning vanus (agea).
Võtame andmestiku SPSSi aknas lahti, valime
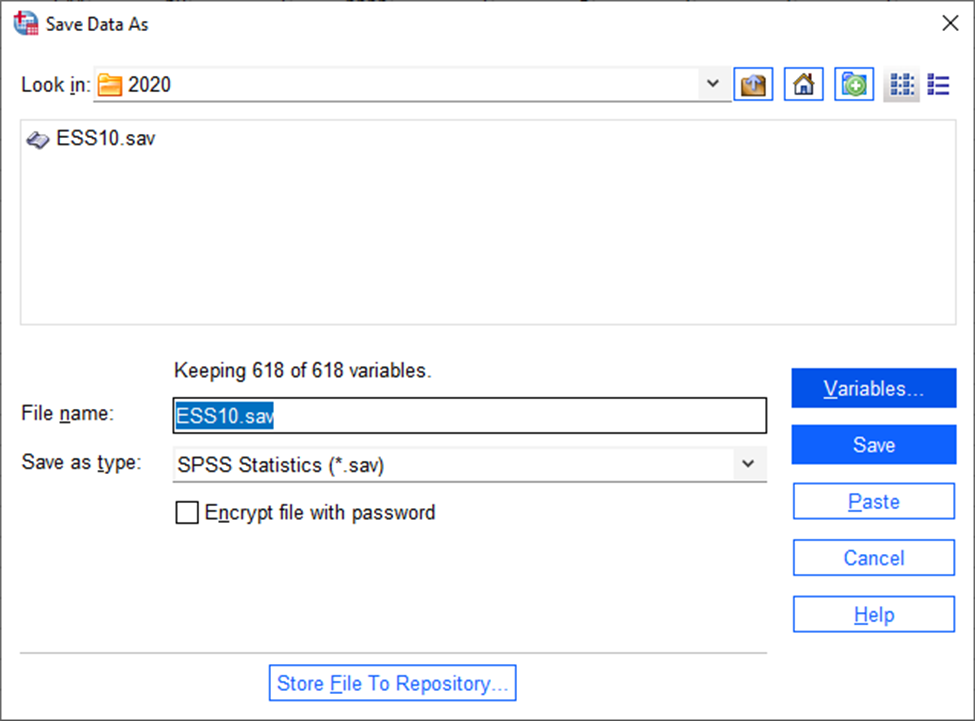
File -> Save as „Save Data As“ aknas vajutame nuppu „Variables“ (Joonis 1).
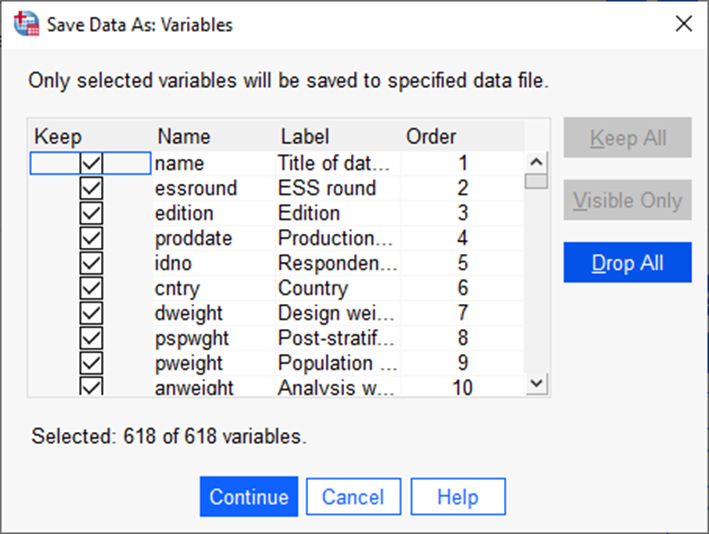
Avanenud aknas näitab veerg „Keep“, millised tunnused võetakse andmestiku salvestamisel uude andmestikku kaasa (Joonis 2). Automaatselt on valitud kõik. Nupp „Drop All“ võtab kõigilt tunnustelt linnukesed eest ära (tekib olukord, kus salvestatavas andmestikus pole ühtegi tunnust) ja saame hakata tunnuseid ükshaaval valima. Kui vajalikud tunnused on valitud, tuleks vajutada „Continue“ ( Joonis 3).
Seejärel tuleks anda uuele andmestikule nimi aknas „File name“ ja valida uue faili asukoht (Joonis 4).
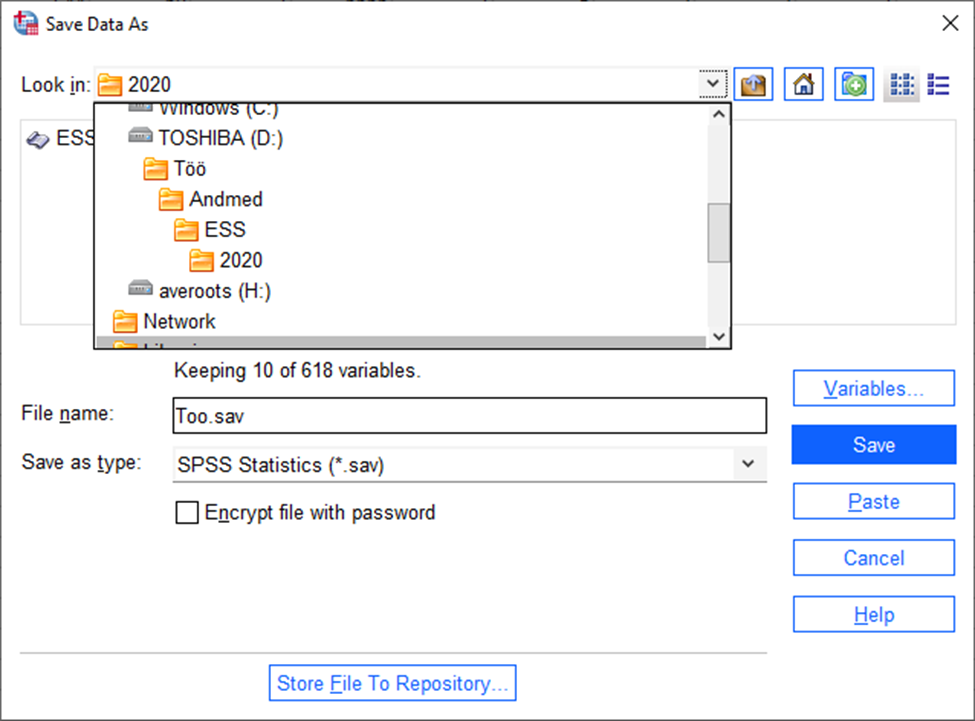
Seejärel tuleb vajutada „Save“.
Ongi uus andmestik salvestatud. See tuleb nüüd SPSSis avada ja seda saab kasutama hakata.
SPSS süntaks R-i käsuridaEelnevas Euroopa Sotsiaaluuringu andmestikus on kõigi vastavas küsitlusvoorus osalenud riikide andmed. Kui soovime kasutada ainult Eesti andmeid, tuleb need andmestikust välja filtreerida.
Selleks avame:
Data -> Select cases
Vajutame sisse nupu „If condition is satisfied ja vajutame nupule „If“ (Joonis 6).
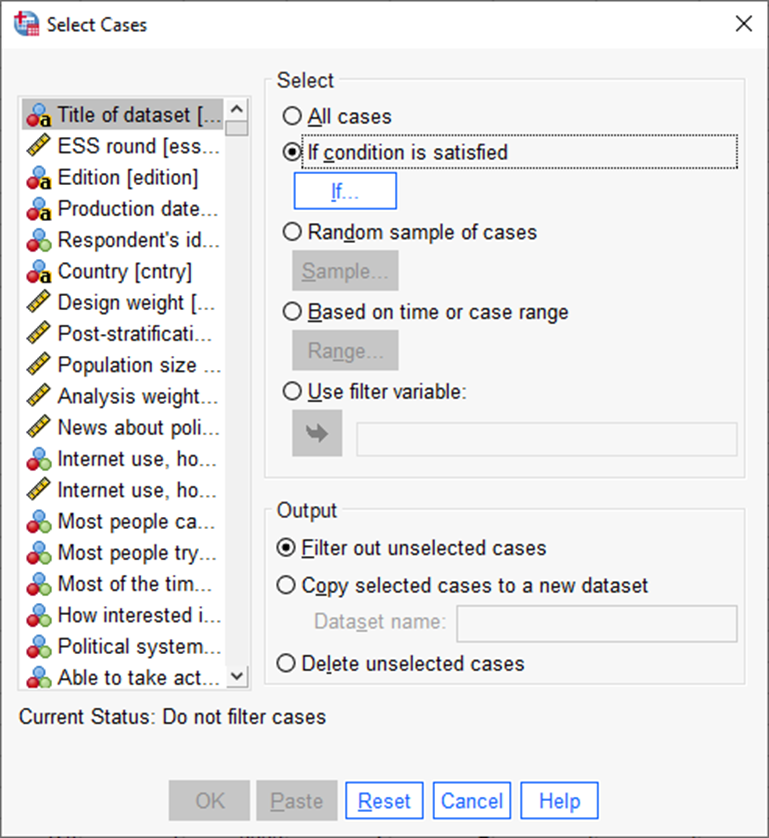
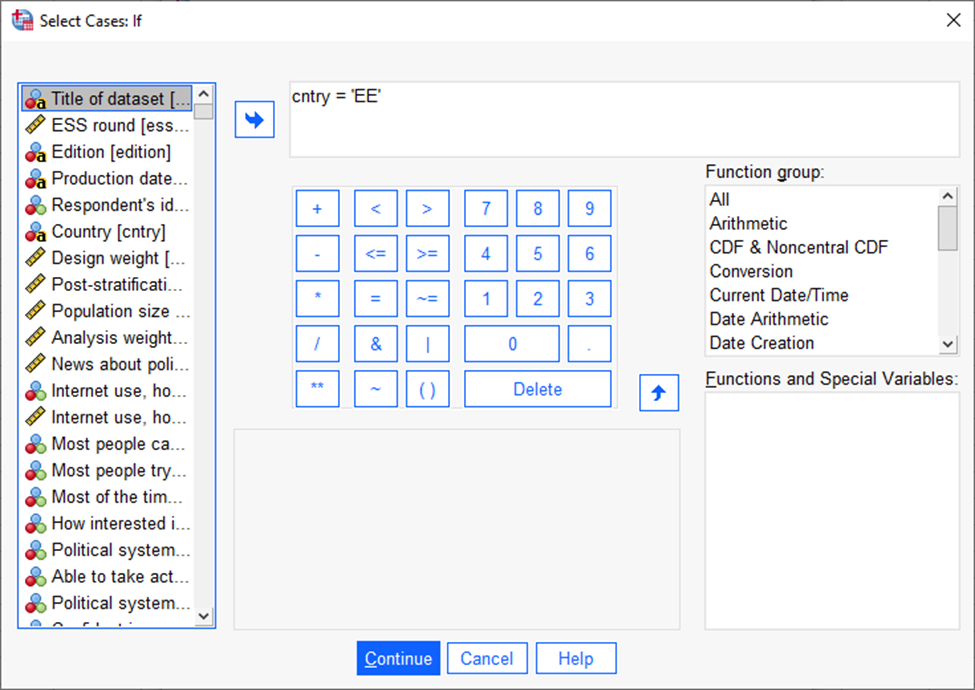
Kirjutame tehteväljale „cntry=’EE’“ ehk riik võrdub Eestiga. „EE“ on vastavas tunnuses olev kood, mis tähistab Eestit[1]. Seejärel vajutame „Continue“ ja järgnevas aknas „OK“ (Joonis 7).
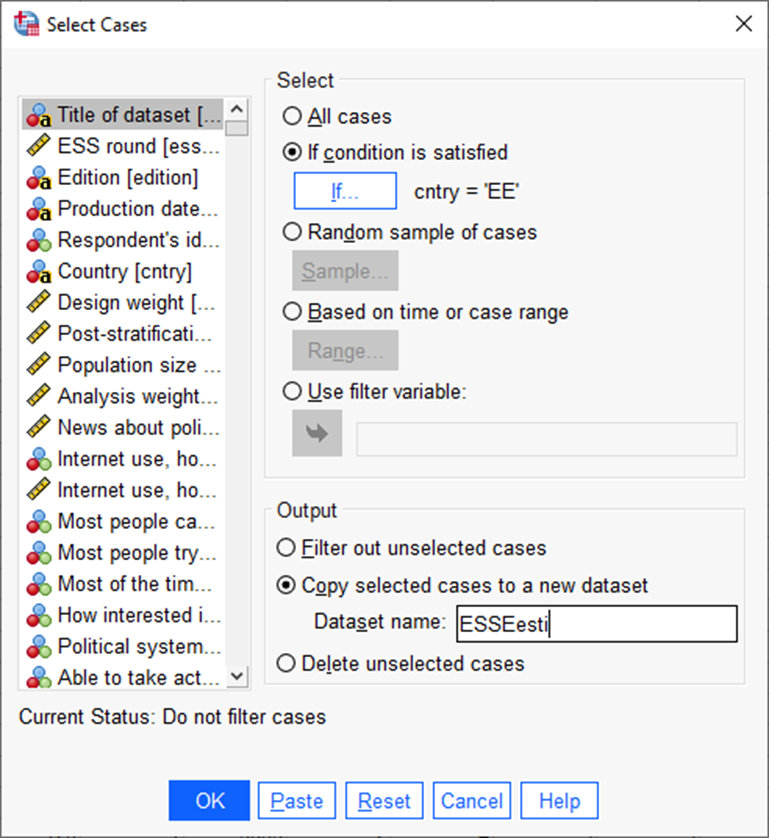
Output valikute all võiks valida saadud andmestiku loomise uue failina („Copy selected cases to a new dataset“[2]) (Joonis 8).
Seejärel vajutada „OK“. Andmestik avatakse uues nimetus aknas, mis tuleks ise uuesti salvestada.
[1] Juhul kui valida „Filter out unselected cases“, jäävad kõik vastajad andmestikku alles, aga analüüsis kasutatakse ainult neid, kes vastavad seatud tingimusele, praegusel juhul siis Eestis elavaid inimesi. Uut andmestikku sel juhul ei looda. Hiljem saab algse olukorra taastada ja jälle analüüse teha kõigi indiviididega, kui joonisel 6 näidatud aknas sektsiooni „Select“ all valida „All cases“. Valides „Delete unselected cases“, tähendab, et andmestikust kustutatakse kõik need vastajad, kes seatud tingimusele ei vasta. Seda muudatust ei ole võimalik tagasi pöörata ehk siis kustutatud indiviide enam tagasi ei saa. Soovitav on seda valikut mitte kasutada. Sellel juhul ka uut andmestikku ei salvestata.
[2] Filtriks on võimalik lisada ka rohkem tingimusi. Näiteks, kui sooviksime moodustada andmestiku Eestis elavatest üle 50-aastastest inimestest, siis tuleks kirjutada järgmine tingimus „cntry=’EE’ & agea>=50“. Siin siis eeldatakse Eestis elamise ja vanuse tingimuse samaaegset kehtimist, mida tähistab märk „&“.
SPSS süntaks R-i käsuridaTahaksime eelnevasse andmestikku liita indiviidi staatuse tööturul.
Selleks teeme liidetava tunnuse faili, kus on ainult need tunnused, mida soovime juurde liita, ning ID, mis peab olema sama mõlemas liidetavas andmestikus (st sama indiviid peab olema sama ID-numbriga, et ühe inimese andmed satuksid ühele reale).
Järgnevalt tuleks võtta ette see andmeaken (põhiandmestiku aken), millele hakkate teist (andmestikku) juurde liitma. Seejärel valige menüüst
Data -> Merge Files -> Add Variables
Liita saab kas juba lahti olevat andmestikku (Joonis 9)
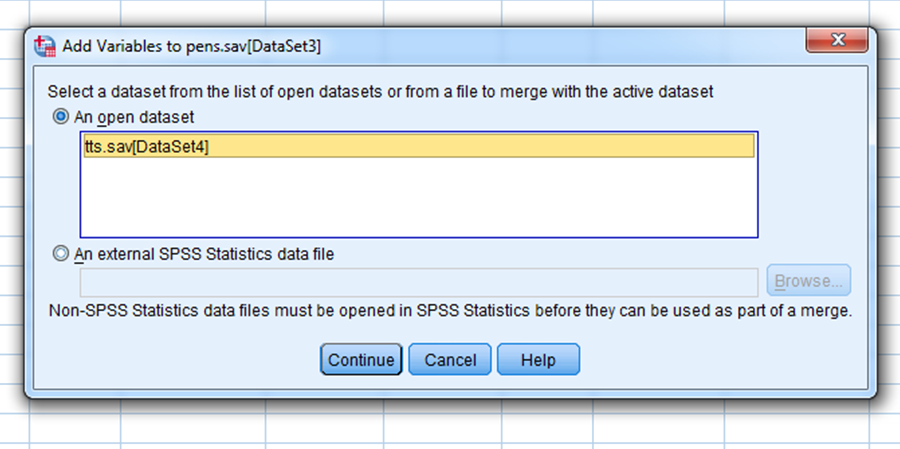
või andmestikku, mis ei ole avatud (Joonis 10).
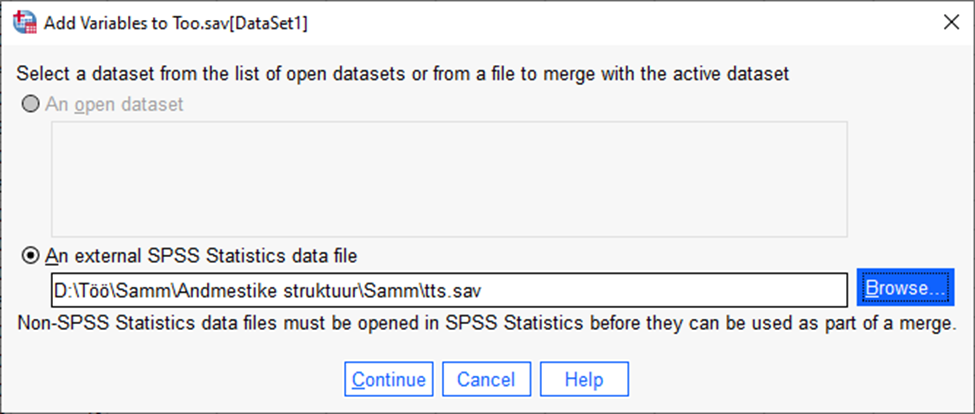
Seejärel vajutada „Continue“.
Selleks, et juurdeliidetavast andmestikust tulevad andmed saaksid sama rea peale, kus on selle indiviidi põhiandmestikus olevad andmed, peab andmestikus olema tunnus, mis on indiviidi eraldav unikaalne kood. See on igal andmestikus oleval indiviidil erinev. ESSi andmestikus on selleks tunnus „idno“. Lisaks tuleks üle vaadata, et on olemas linnukesed „One-to-one megre based on key values“ ja „Sort files by key values before merging“ ees (Joonis 11) ehk siis andmestik liidetakse teatud tunnuse alusel ning peab olema selle sama tunnuse alusel ka sorteeritud.
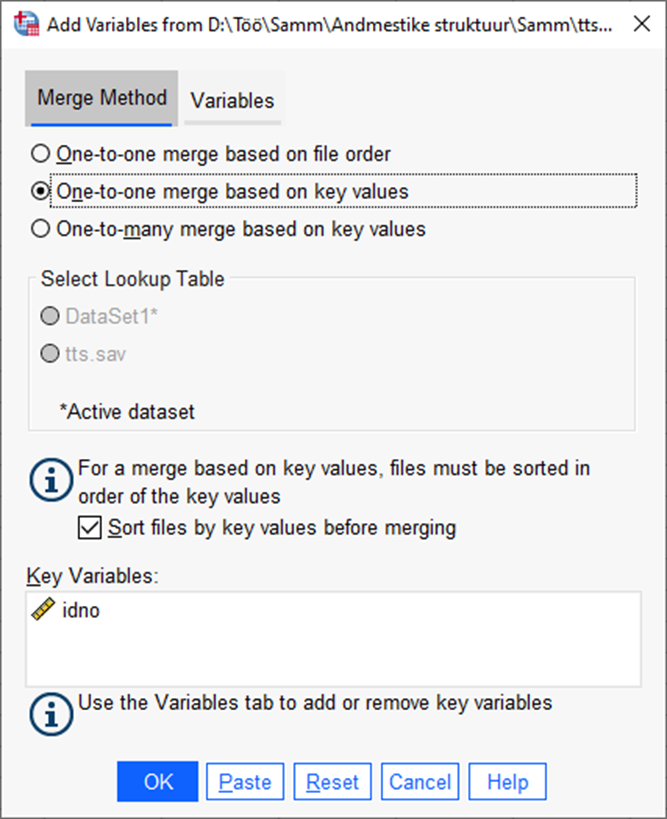
Seejärel vajutada „OK“.
SPSS süntaks R-i käsuridaEnne olid andmestikus vaid Eesti andmed, kuid kui tahaksime teha võrdlust näiteks Eesti ja Soome vahel, tuleks Eesti andmetele liita ka Soome andmestiku samad tunnused. Selline tehe eeldab, et mõlemas failis, mida tahame kokku panna, on tunnustel samad nimed.
Valida menüüst Data -> Merge Files -> Add Cases
Valida lisatav fail (Joonis 12).
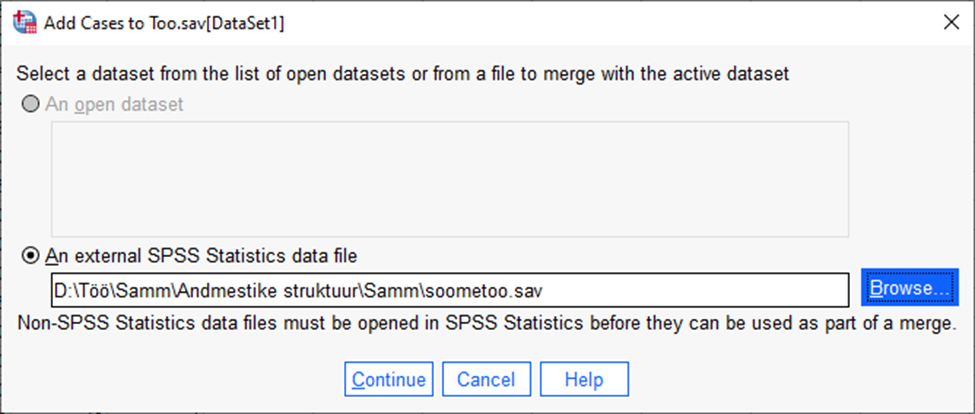
Valida „Continue“.
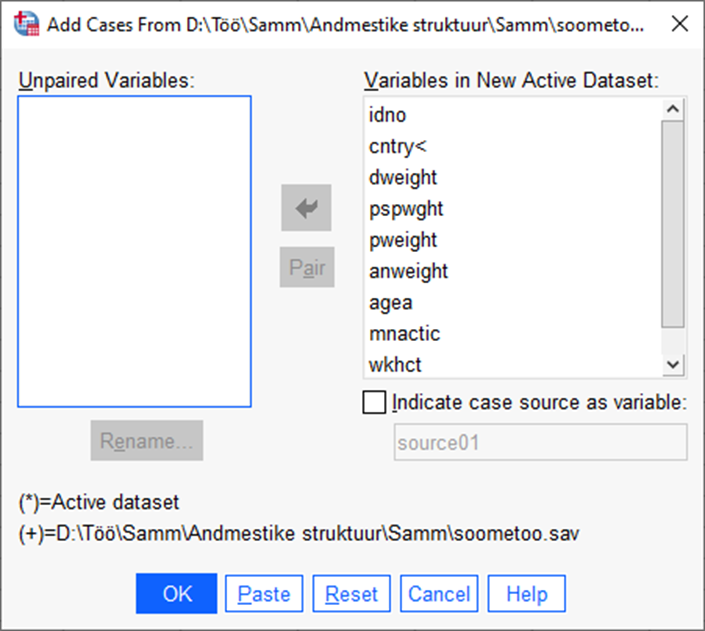
Valida „OK“.
Kui failides on erineva nimega tunnused, siis need ilmuvad aknas „Unpaired Variables“. Kui on siiski tegemist samade tunnustega, millel on eri andmestikes erinev nimi, siis tuleks üks tunnustest ümber nimetada ja nad saab saata kõrvalaknasse. Kui on tegemist tunnustega, mis ühes andmestikus on ja teises ei ole, siis need kustutatakse ja lõppandmestikus ei kajastu. Seega on lõppandmestikus ainult need tunnused, mis on sama nimega mõlemas andmestikus. Andmestike liitmisel tuleks olla tähelepanelik, et tunnused on mõlemas andmestikus sama skaalaga. Vajadusel tuleb skaala ümber kodeerida.
SPSS süntaks R-i käsuridaVõib juhtuda, et andmestik ei ole sellises formaadis, nagu meie analüüsi jaoks tarvis on. Näiteks võib juhtuda, et ühe indiviidi andmed on ühe asemel mitmel real (iga kordusmõõtmine eraldi real) või on andmestikus tarvis ära vahetada read ja veerud. Järgnev osa puudutabki andmete struktuuri muutmist, käsitledes andmestiku ridade ja veergude vahetamist ning pikkformaadi laiformaadiks muutmist ja vastupidi.
Sellist andmestiku muutmist võib olla vaja, kui soovite analüüsiühikuna kasutada seda, mis algandmestikus on veergudes ehk siis käsitletud tunnustena. Näiteks juhul, kui meil on andmed seaduseelnõude ja parlamendisaadikute kohta ja meil on analüüsiühikuks seaduseelnõu ning meid huvitavad hääletustulemused lähtuvalt teatud eelnõude omadustest, siis on meil ridades seaduseelnõud ja veergudes parlamendisaadikud. Kui meid huvitab teatud tüüpi parlamendisaadikute hääletuskäitumine, siis on meil vaja andmestikku, mille ridades on parlamendisaadikud ning veergudes seaduseelnõud.
Allolevas näites on andmestikus algselt ära toodud vastaja leibkonnas olevad pereliikmed. Kui soovime teha pereliikmetest lähtuva analüüsi, siis pöörame andmestiku nii, et pereliikmed jäävad ridadesse ja vastajate numbrid veergudesse.
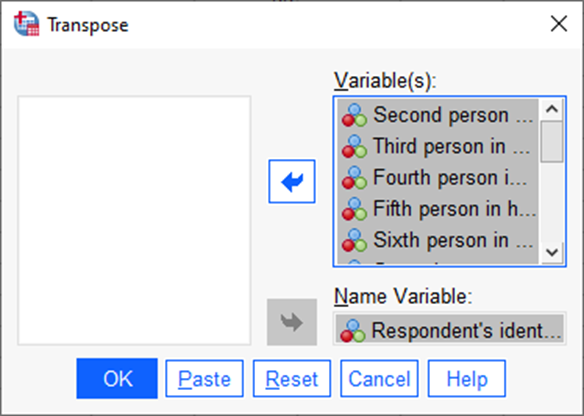
Valime menüüst Data -> Transpose
Aknasse „Variables“ tuleb saata tunnused, mida soovitakse pöörata. Praegusel juhul on selleks Euroopa Sotsiaaluuringu Eesti 2020. aasta andmetes leibkonnaliikmete suhe respondendiga (st kas on abikaasa, laps jne). Aknasse „Name Variable“ tuleb saata tunnus, mille järgi nimetatakse veerge uues andmestikus, vaadeldaval juhul on selleks vastaja number idno (Joonis 14).
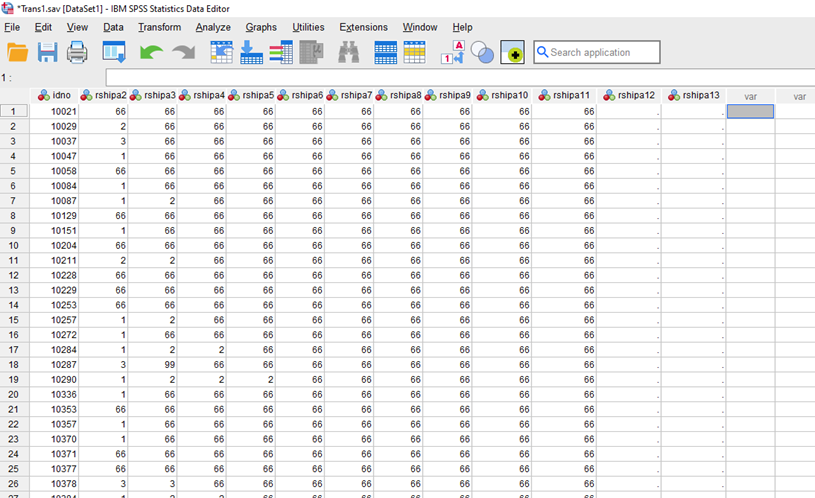
Algses andmestikus on tunnused veergudes ja respondendid ridades (Joonis 15).
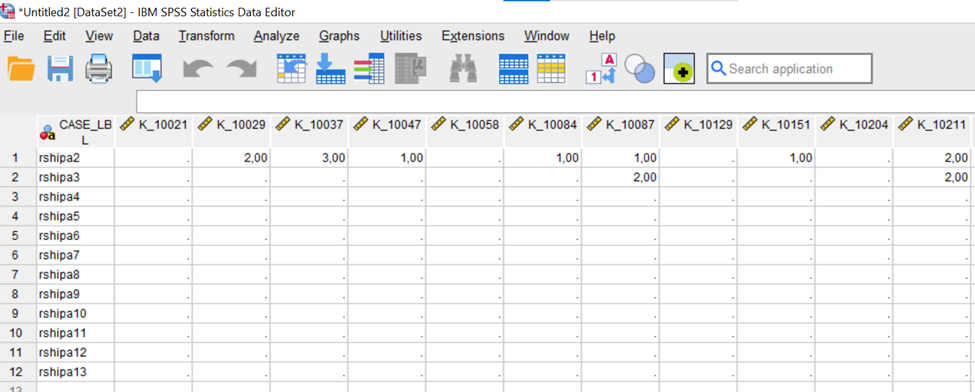
Pööratud andmestikus on veergudes indiviidid ja ridades tunnused (Joonis 16).
Kõige laialdasemalt kasutatav andmeformaat on laiformaat, kus ühe indiviidiga (või mõne muu analüüsiühiku, nt riigiga) seotud andmed on kõik ühel ja samal real. Mõningatel juhtudel – tulenevalt andmeanalüüsiprogrammi loogikast või longituudandmete puhul – võib aga vaja minna pikkformaati, nt kui on mõõdetud eri töötusperioodide pikkust. Meie jaoks ei ole oluline, mitu korda üks inimene töötu oli, me tahame uurida hoopis tegureid, mis mõjutavad töötusperioodide pikkust, olenemata sellest, mitmenda töötusega on tegemist. Sellisel juhul tahame, et sama indiviidi töötusperioodid oleks igaüks eraldi real ja seega näiteks selle inimese kohta, kes on kolm korda töötu olnud, on meil andmestikus kolm andmerida.
Praegusel juhul on meil algandmestikus veergudes tunnused ja iga rea peal on eri indiviidi andmed. Andmestik näeb välja selline nagu näidatud joonisel 17.

Soovime muuta andmete struktuuri nii, et sama indiviidi leibkonnaliikmed tuleksid üksteise all järjest.
Valida menüüst Data -> Restructure
Võtta esimene valik, nagu on näha joonisel 18.
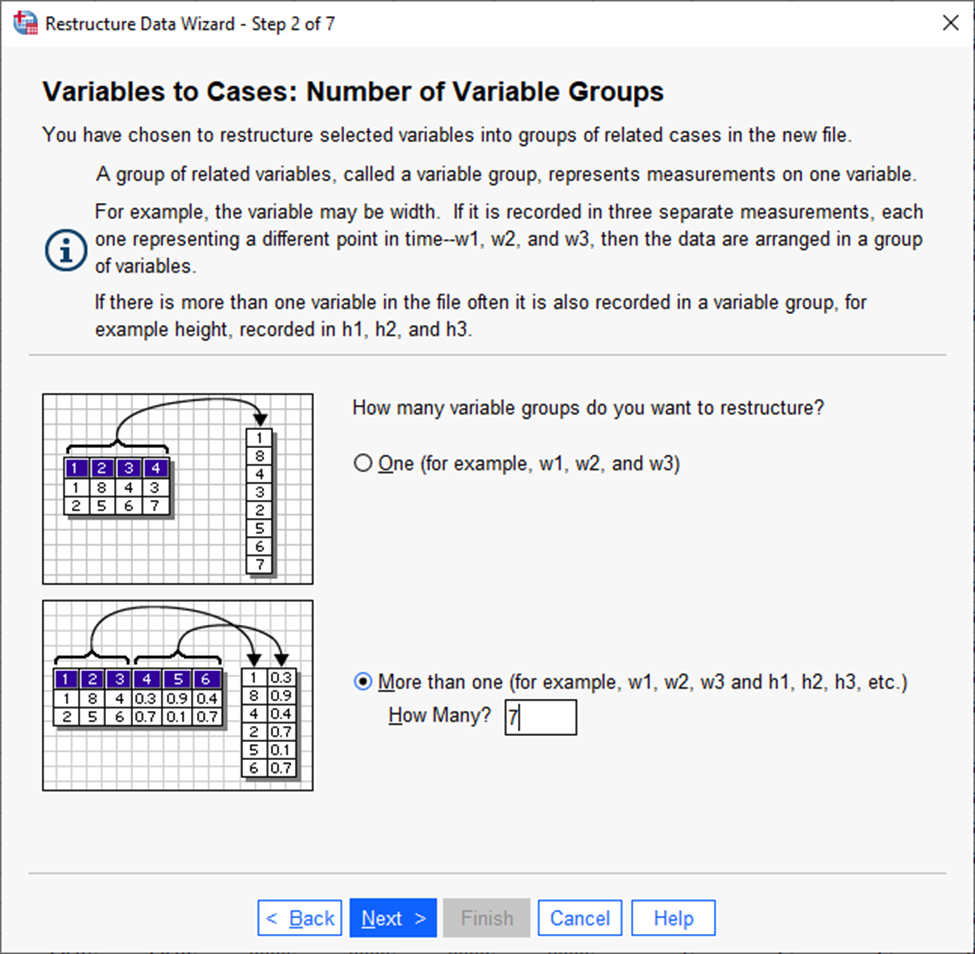
Kuna tegemist on seitsme tunnuste grupiga (meil on seitsme erineva leibkonnaliikme andmed, mis grupeeritakse), siis tuleb järgnevas aknas valida alumine valik ja märkida lahtrisse „How Many“ (Joonis 19). Seejärel vajutada nupule „Next“.
Seejärel tuleb valida, millised tunnused kuuluvad ühte gruppi. Kõigepealt valida aknas „Target Variable“ „transs 1“ ja seejärel saata selle all olevasse aknasse esimesse gruppi kuuluvad tunnused, vaadeldaval juhul respondendi sugu, sünniaasta ja suhe respondendiga, nagu näidatud joonisel 20.
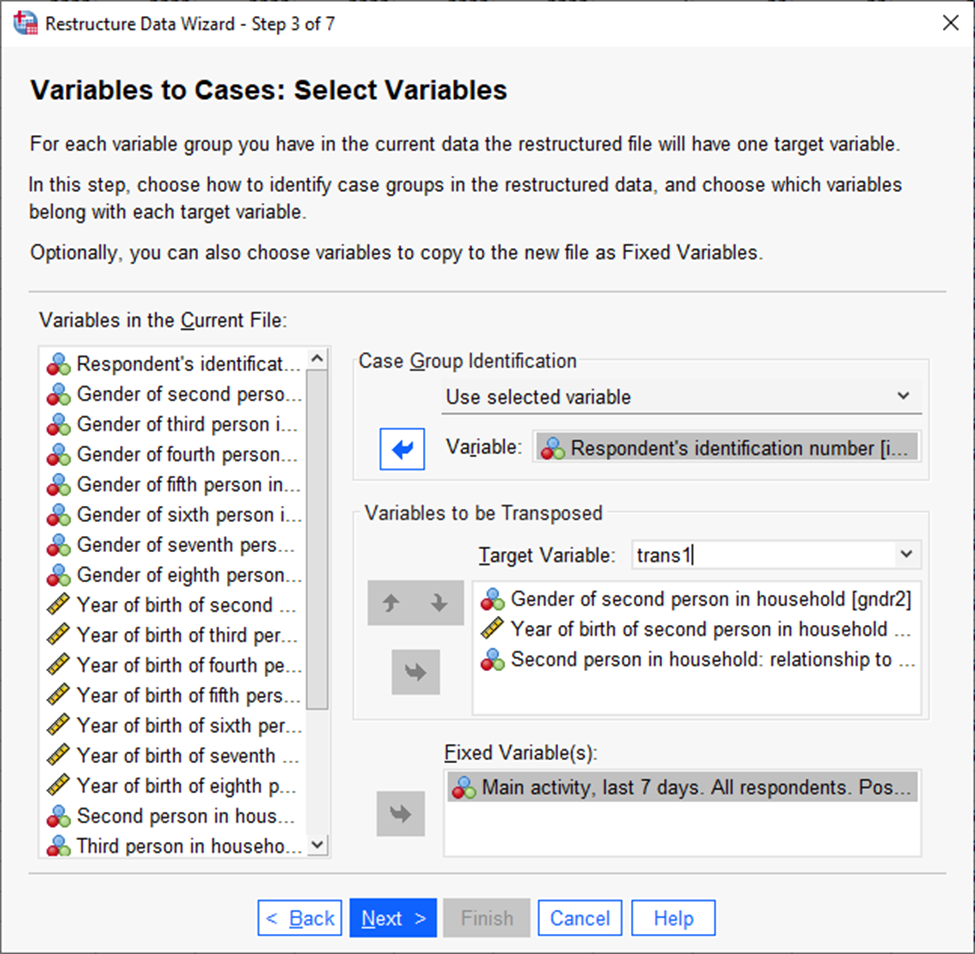
Seejärel tuleks samas aknas valida transs 2 ja saata alumisse aknasse järgmisesse gruppi kuuluvad tunnused (teise leibkonnaliikme sugu, sünniaasta ja suhe respondendiga).
„Case group identification“ näitab ära, mis on ühte gruppi identifitseeriv tunnus (Joonis 21). Kasutame sellena respondenti identifitseetivat tunnust. Selleks valime „Use selected variable“ ja saadame idno tunnuse vastavasse aknasse. Juhul, kui seal jätta vaikesäte „Use case number“, grupid lihtsalt nummerdatakse järjekorranumbritega.
„Fixed variables“ on need tunnused, mis jäävad andmestikku muutmata kujul, st nad lähevad iga grupiga kaasa algsel kujul, vajadusel need lihtsalt kopeeritakse.
Kui kõik grupid on defineeritud, saab vajutada nupule „Next“.
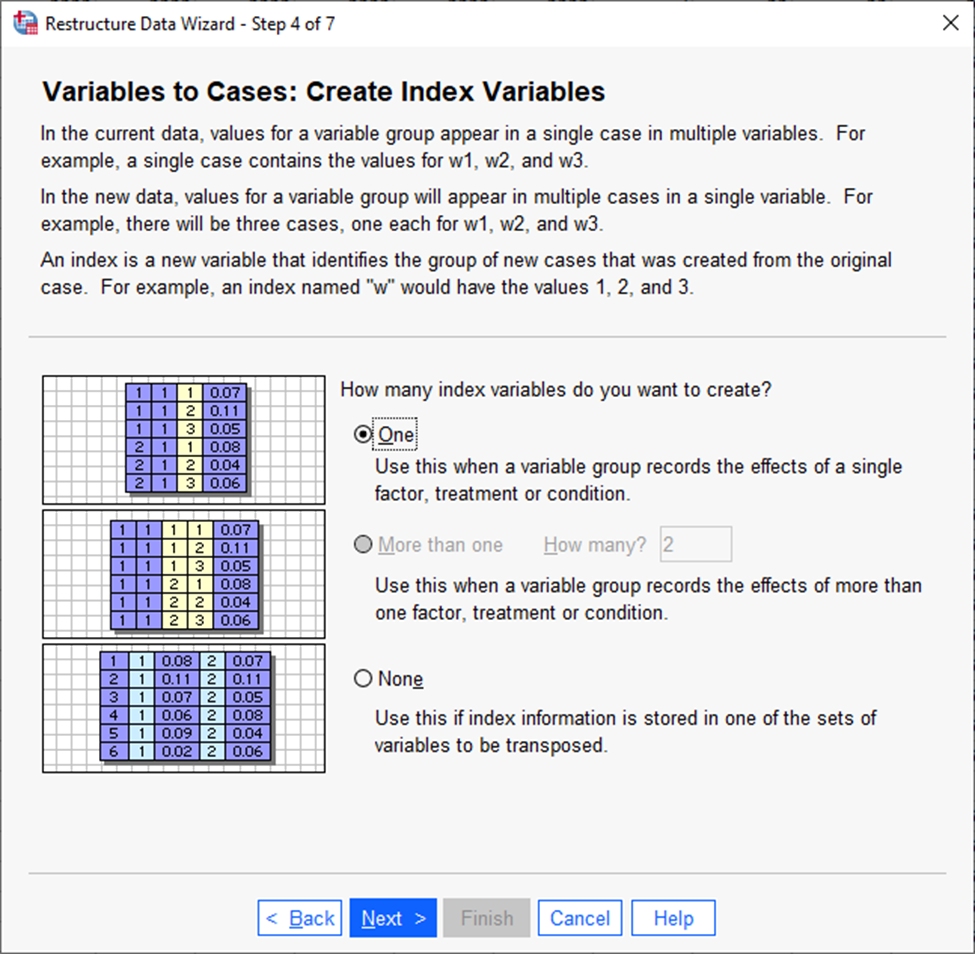
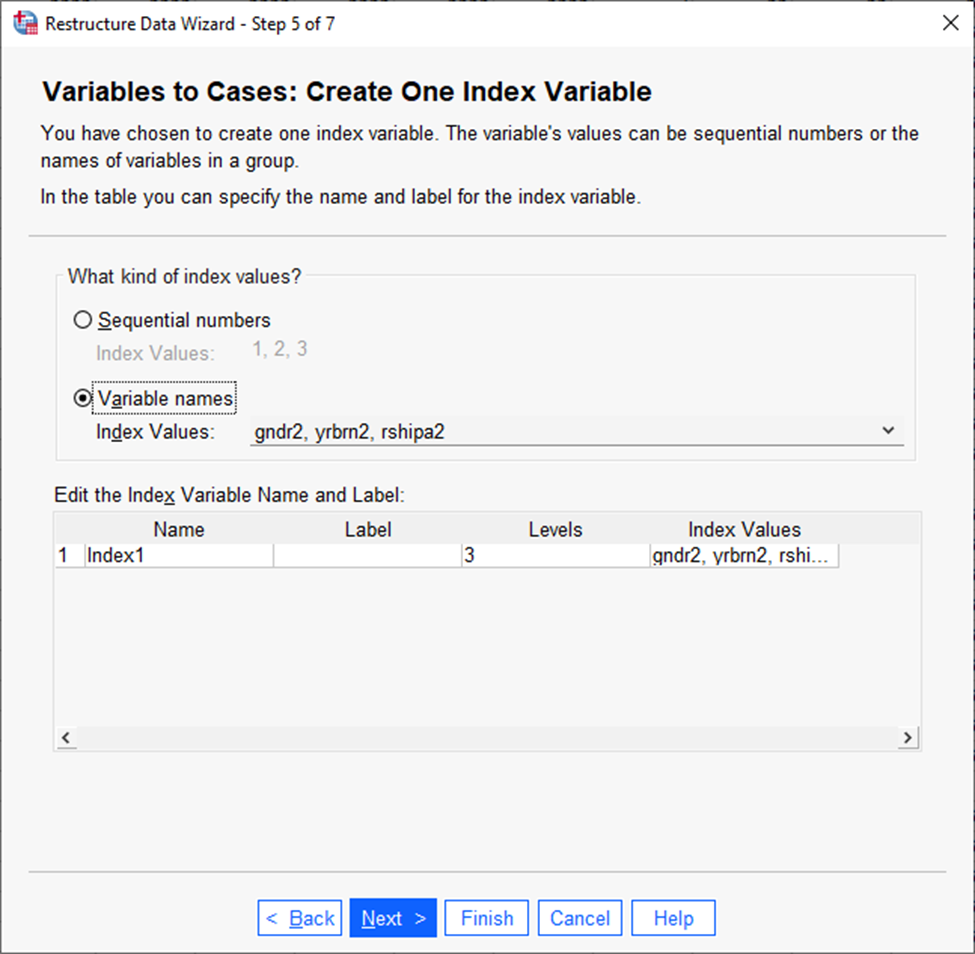
Jätame siin automaatvaliku ehk siis ühe indekstunnuse ning vajutame uuesti „Next“.
Et säiliksid ka algsed tunnuste nimed, saab need salvestada eraldi tunnusesse; selleks valida järgmises aknas „Variable names“ (joonis 22).
Seejärel valida „Next“ ja veel kord „Next“.
Järgnevas aknas on võimalik valida, kas tahetakse andmeid muuta kohe või kõigepealt saada süntaks ja seejärel see käivitada (Joonis 23).
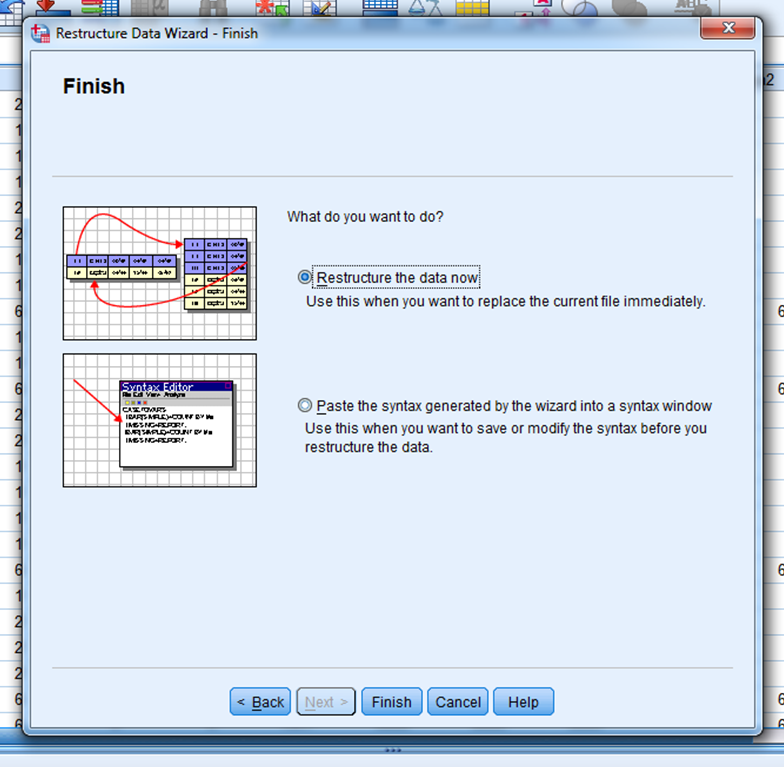
Pärast selle valiku langetamist vajutada „Finish“.
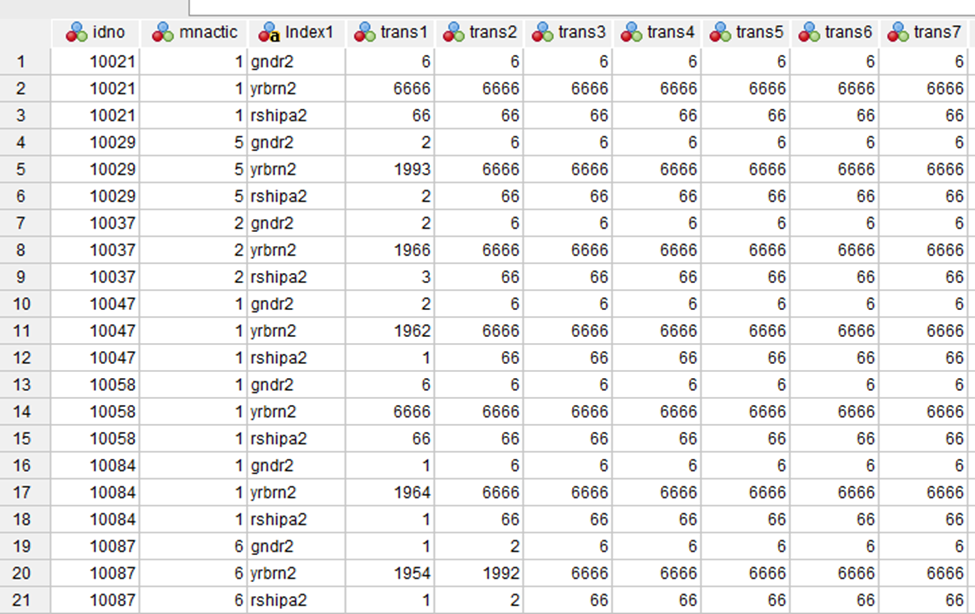
Tulemuseks on andmestik, kus ühe respondendiga seotud andmed ei ole enam ainult ühel real, vaid kolmel real, ühel real on kõigi selles andmestikus olevate leibkonnaliikmete sugu, teisel kõigi sünniaasta ja kolmandal suhe respondendiga (Joonis 24). ID-tunnus näitab leibkonna numbrit, st samasse leibkonda kuuluvatel inimestel on see sama.
Järgmisena vaatame eelnevale vastupidist andmete struktuuri muutmist.
Valida menüüst Data -> Restructure
Märkida ära teine valik (Joonis 25).
Järgmisena tuleb see tunnus, mille järgi uued read moodustatakse (ehk siis indiviidi ID, kuna tahame, et sama indiviidi andmed läheksid kõik ühele reale), panna lahtrisse „Identifier Variables“ ja see tunnus, kust võetakse pikkformaadi tunnuste nimed, panna lahtrisse „Index Variables“ (Joonis 26).
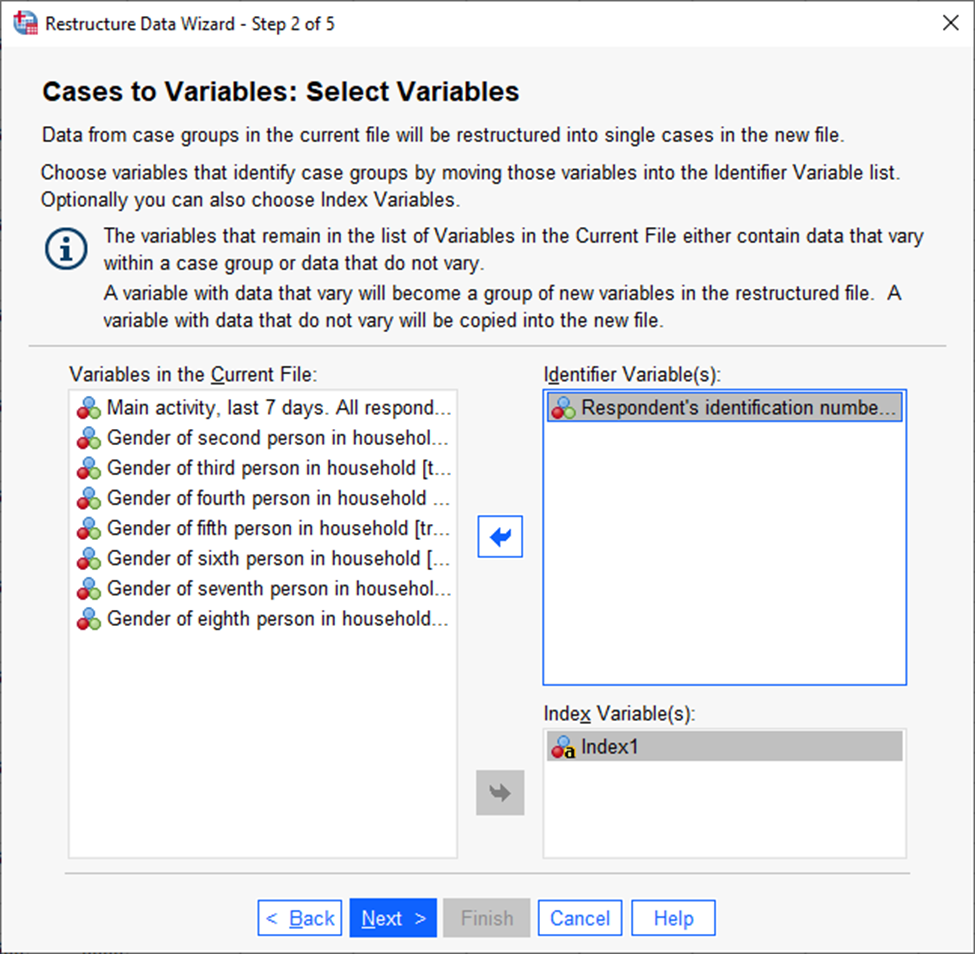
Seejärel võib kolm korda „Next“ vajutada ja originaalvalikud samaks jätta. Lõpuks antakse taas valida, kas soovitakse andmeid kohe muuta või kõigepealt saada süntaks. Pärast selle valiku langetamist ja sellel lehel „Finish“ vajutamist ongi tulemuseks uue struktuuriga andmebaas.
Uus andmestik näeb välja nii, nagu on näha jooniselt 27.
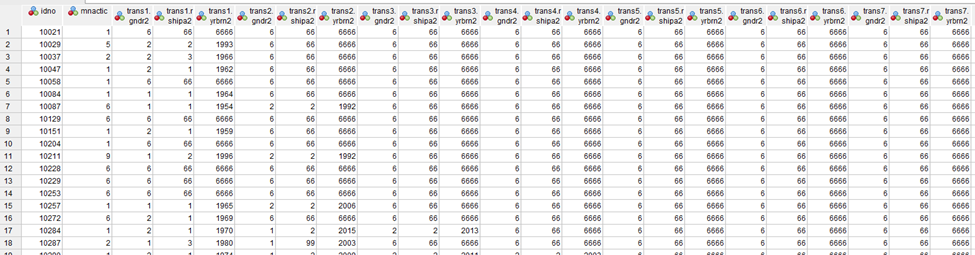
Tahaksime kokku kodeerida Euroopa Sotsiaaluuringu 2020. aasta Eesti andmestikus oleva tööturu staatust näitava tunnuse kategooriaid.
Menüüst tuleks võtta:
Transform -> Recode into Different Variables
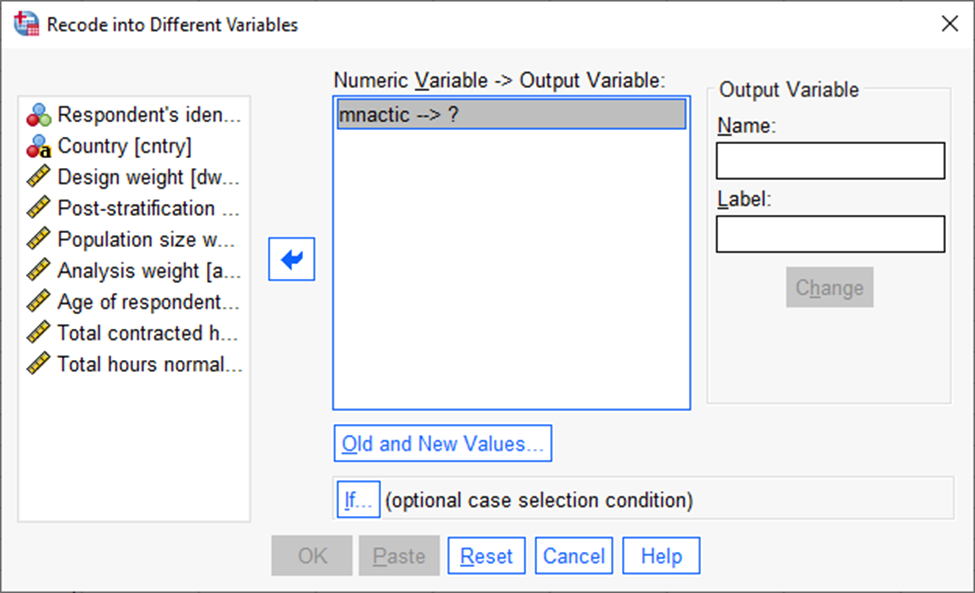
Valida välja tunnus, mida tahame ümber kodeerida (mnactic), ja saata see keskmisse aknasse (Joonis 28).
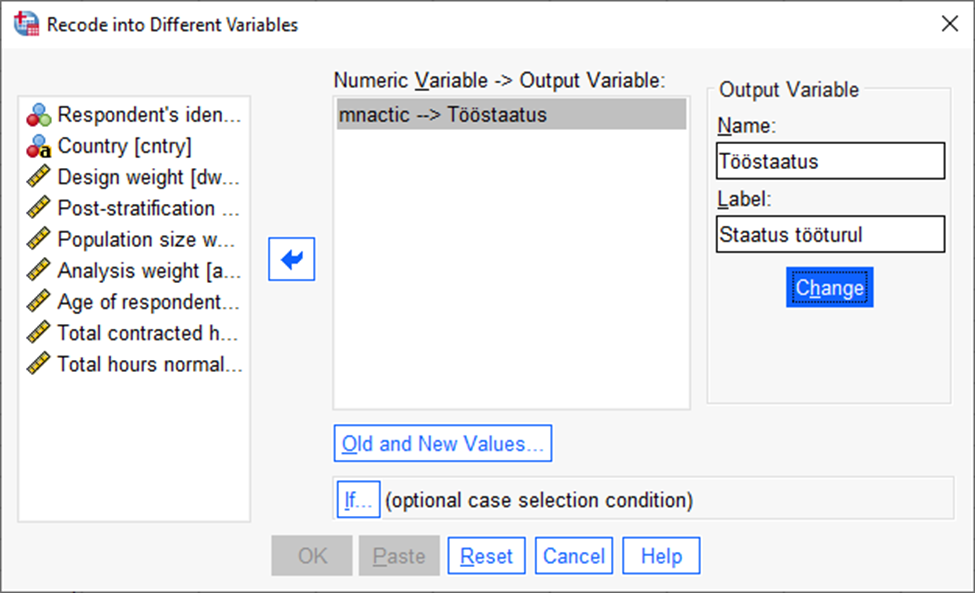
Seejärel anda uuele tunnusele nimi lahtris „Name“ ja vajutada „Change“. Ilma „Change“ vajutamata uus tunnus ei salvestu (Joonis 29). Võib lisada ka tunnuse pikema kirjelduse lahtrisse „Label“. Järgmisena tuleb vajutada nupule „Old and New Values“, kus saab määrata uue tunnuse väärtused valitud tunnuse väärtustest lähtuvalt.
Tunnuse originaalskaala on järgmine:
- tasustatud tööl või ajutiselt tööst eemal (töövõtja, eraettevõtja, töötate perefirmas);
- õpite (tasustamata tööandja poolt) või õpingutest ajutisel puhkusel;
- töötu ja otsite aktiivselt tööd;
- töötu, kuid ei otsi aktiivselt tööd;
- püsivalt töövõimetu või puudega;
- pensionil;
- kohustuslikul ühiskondlikult kasulikul tööl või ajateenistuses;
- kodune, hoolitsete laste või kellegi teise eest;
- (MUU);
88 (EOÖ).
Avanenud aknas tuleb deklareerida ühe kaupa kategooriate vanad (nimekirjas tunnuse ees olevad koodid) ja uued väärtused (meie soovitavad koodid uuele, tekkivale tunnusele) ja igal korral vajutada „Add“ (Joonis 30).
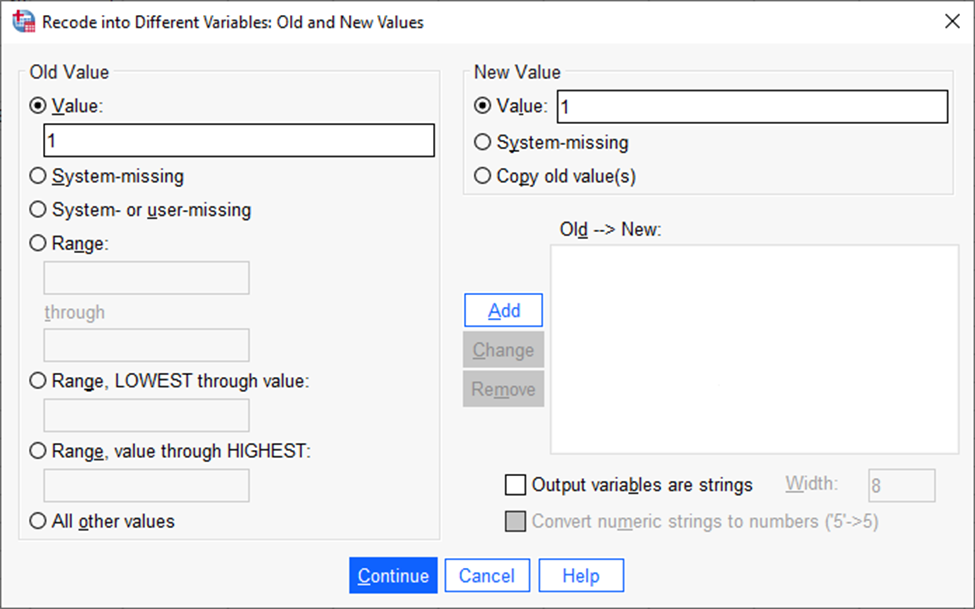
Vana väärtuse aknas on mitu valikut. „System-missing“ tähendab deklareerimata puuduvatele väärtustele mingi uue väärtuse andmist.
„System- or user-missing“ tähendab nii deklareeritud kui ka deklareerimata puuduvatele väärtustele mingi uue väärtuse andmist.
„Range“ alla saab määratleda mingi väärtuste vahemiku (nt 3–4, ülemisse kasti 3 ja alumisse 4).
„Range, lowest through value“ tähendab, et võetakse vahemik olemasoleva tunnuse kõige madalamast väärtusest kuni väärtuseni, mis kasti märgitakse.
„Range, value through highest“ tähendab, et võetakse kasti märgitud väärtusest kuni olemasoleva kõige kõrgema väärtuseni.
„All other values“ saab anda mingi konkreetse väärtuse kõigile neile väärtustele, mida pole enne mainitud.
Uue väärtuse aknas „System missing“ tähendab, et mingi olemasoleva väärtuse saab muuta puuduvaks väärtuseks, ning „Copy old values“ tähendab, et vanade väärtuste all deklareeritud konkreetsed koodid jäävad ka uues tunnuses samaks. Toodud näite puhul võiks seda rakendada koodide 1 ja 2 puhul.
Kui väärtuste defineerimine on valmis, vajutada „Continue“ (joonis 31).
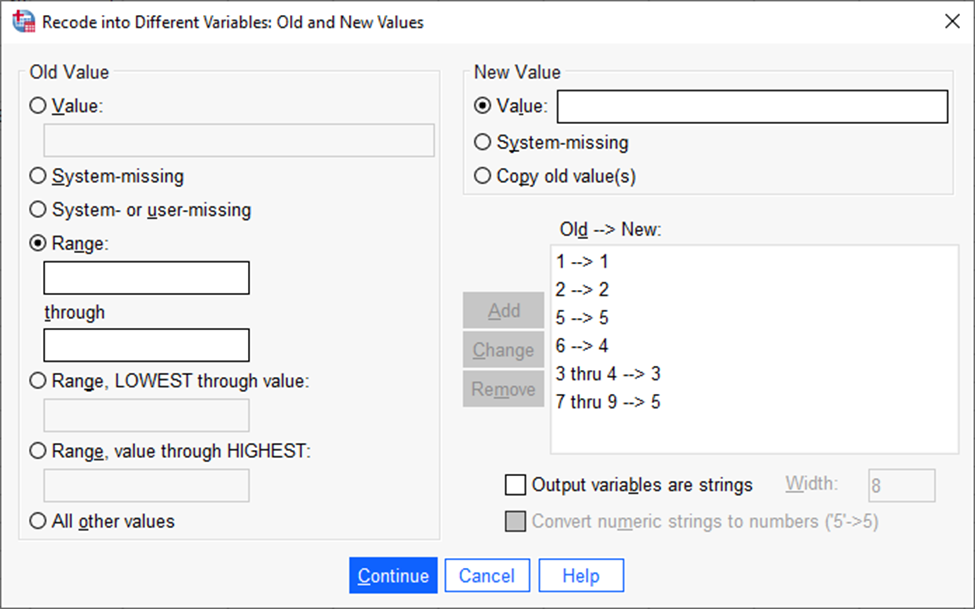
Siis vajutada „OK“.
Andmestiku lõppu tekkiski uus tunnus.
Tunnuse kategooriate kirjeldamiseks võtta ette „Variable View“. Klõpsata vastava tunnuse „Values“ veerus oleval lahtril (Joonis 32).
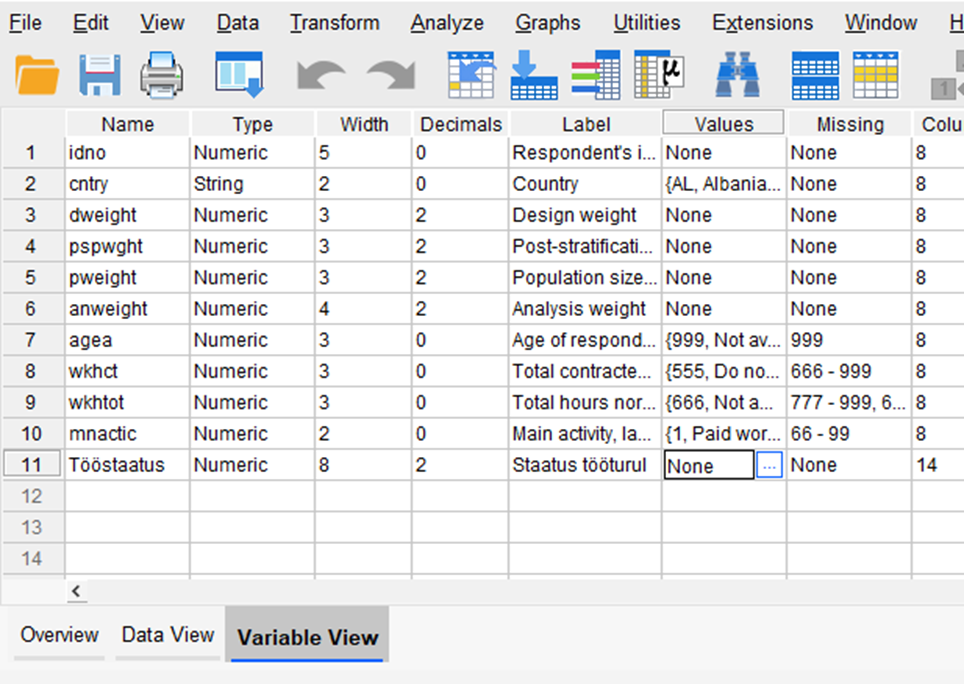
Avanenud aknas tuleb „+“ nupust lisada rida ning sisestada veergu „Value“ kategooria väärtus ja veergu „Label“ kategooria nimetus (nagu näha joonisel 33). Samamoodi defineerida kõik tunnuse kategooriad.
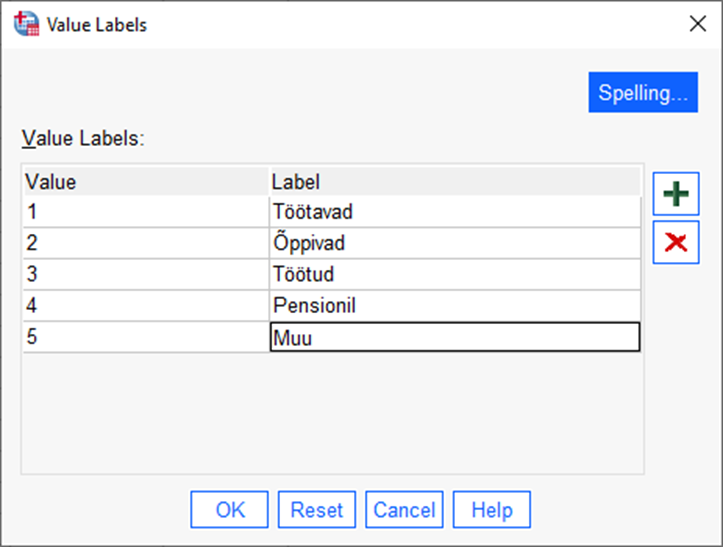
Kui kõik kategooriad on defineeritud, vajutada „OK“.
SPSS süntaks R-i käsuridaLoome uue tunnuse mõne muu tunnuse vahelise arvutustehte tulemusena.
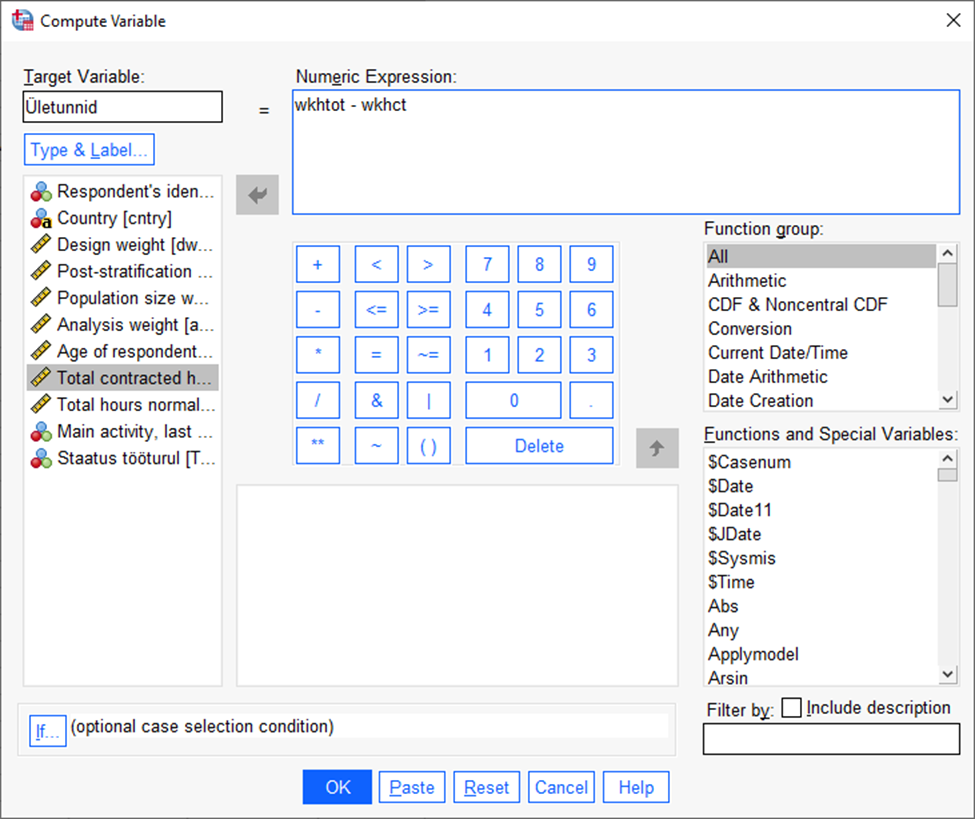
Oletame, et soovime teada, kui suur on inimeste lepingujärgsete töötundide ja tegelike töötundide vahe.
Võtame menüüst Transform -> Compute Variable
Avanenud aknas (Joonis 34) kirjutame lahtrisse „Target variable“ uue tunnuse nime ja lahtrisse „Numeric Expression“ tehte, mille põhjal uus tunnus arvutatakse. Antud juhul on selleks tegelike töötundide ja lepingujärgsete töötundide vahe. Seejärel tuleb vajutada „OK“.
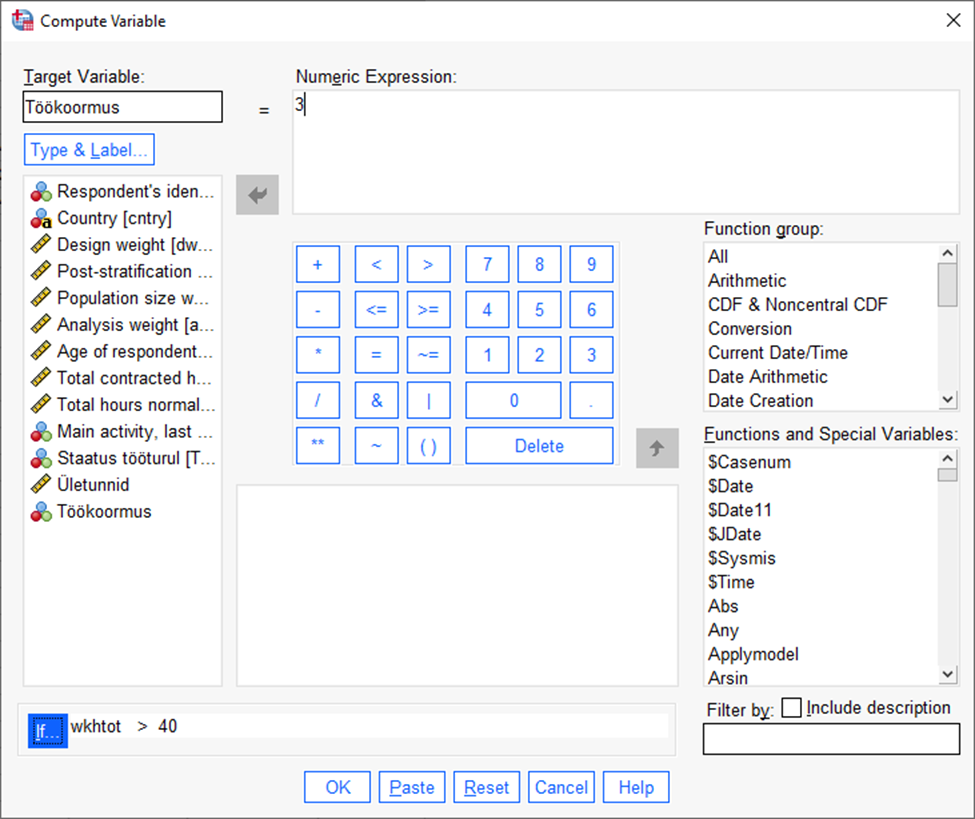
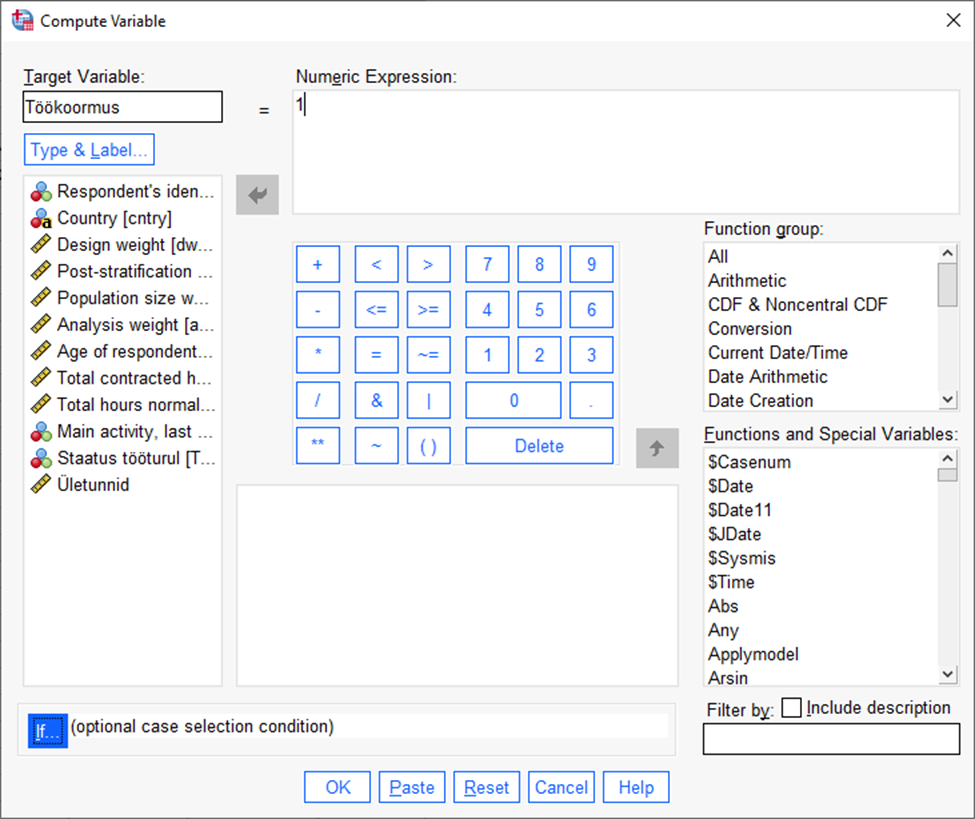
Oletame, et soovime luua tunnust, millel on 3 kategooriat: need, kes töötavad alla 40 tunni nädalas, need kes töötavad 40 tundi nädalas ja need, kes töötavad üle 40 tunni nädalas.
Alustame jällegi Transform -> Compute Variable
Avanenud aknas kirjutame uue tunnuse nime lahtrisse „Target variable“ ning kategooria tähise väljale „Numeric expression“ (Joonis 35). Seejärel vajutame nuppu „If“, et defineerida tingimus, mille korral vastav kategooria luuakse.
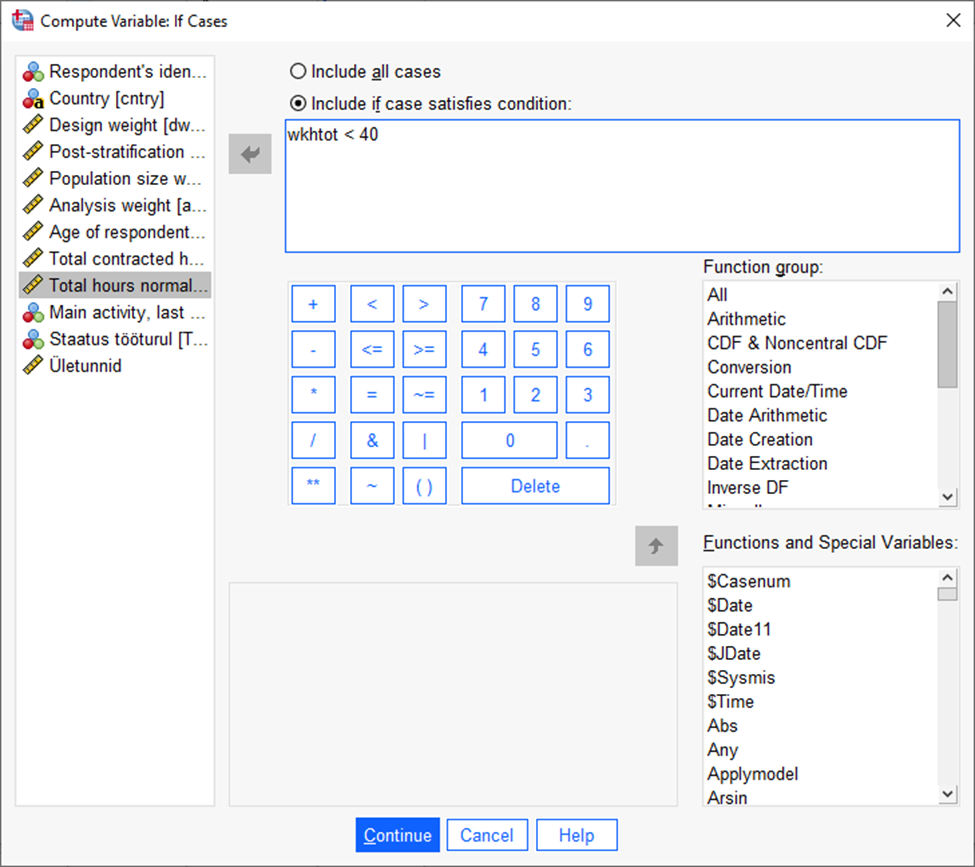
Avanenud aknas vajutame sisse nupu „Include, if case satisfies condition“ (Joonis 36). Seejärel saadame vastavasse aknasse tegelike töötundide tunnuse ja määrame selle väiksemaks kui 40. Seejärel vajutame „Continue“ ning seejärel „OK“.
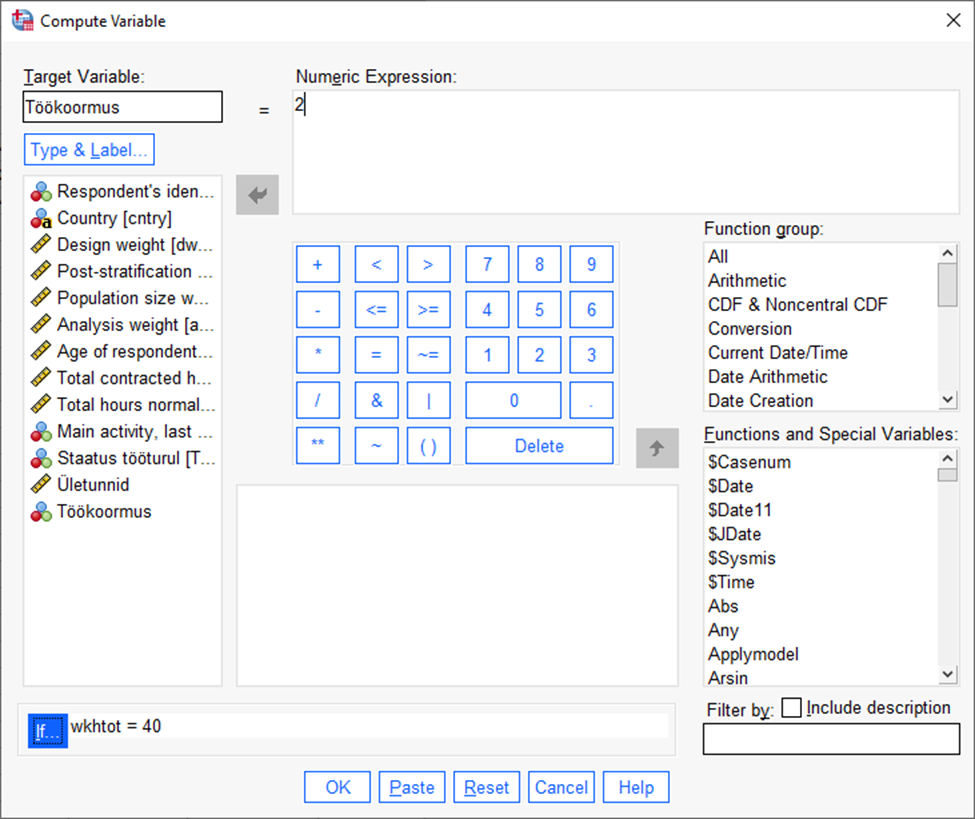
Järgneva kategooria moodustavad need, kes töötavad 40 tundi nädalas (Joonis 37). Tunnuse nimi jääb samaks, aga muutuvad kategooria number ja kategooriat defineeriv tingimus. Seejärel vajutame taas „OK“; kui programm küsib, kas võib muuta olemasolevat tunnust, vastame samuti „OK“.
Viimaks loome ka selle kategooria, kuhu kuuluvad need, kas töötavad üle 40 tunni nädalas (Joonis 38).